# 请求库的封装
# 背景
虽然前端具有诸多成熟的请求库,但在实际项目开发中发现,它们很难完全契合实际的开发需求。
axios
axios虽然很成熟,但它只是一个基础库,没有提供诸多的上层功能,比如:
- 请求重试
- 请求缓存
- 请求幂等
- 请求串行
- 请求并发
- ...
VueRequest / SWR
它们虽然提供的功能很多,但仍然存在诸多问题:
- 与上层框架过度绑定导致开发场景受限,也无法提供统一的API
- 成熟度不够,issue的回复也难以做到及时,存在一定风险
- 它们没有聚合基础请求库,仍然需要手动整合
除此之外更重要的是
公共库不包含公司内部制定的协议规范,即便使用公共库,也必须针对它们做二次封装。
综上,需要自行封装一套适配公司业务的前端请求库
# 方案和实现
# 库结构的宏观设计

整个库结构包含三层,从下往上依次是:
请求实现层: 提供请求基本功能request-core: 提供网络上层控制,比如请求串行、请求并行、请求重试、请求防重等功能request-bus: 为请求绑定业务功能,该层接入公司内部协议规范和接口文档,向外提供业务接口API
层是一种对代码结构的逻辑划分,在具体实现上可以有多种方式:
- 每个层一个npm包
- 每个层一个项目子文件夹
- ...
优化设计
在三层中,请求实现层的实现有多种方式:
- 基于
XHR原生 - 基于
fetch原生 - 基于
axios等第三方库
这种实现的多样性可能导致这一次层的不稳定,而request-imp是基础层,它的不稳性会传导到上一层。
所以必须寻求一种方案来隔离这种不稳定性。
我们可以基于DIP(Dependence Inversion Principle,依赖倒置原则),彻底将request-core和请求的实现解耦,而typescript的类型系统让这一切的落地成为了可能。
于是结构演变为:

下面是示意代码
request-core代码示意
// 定义接口,不负责实现
export interface Requestor {
get(url:string, options:RequestOptions): Promise<Response>
// 略...
}
// 本模块的大部分功能都需要使用到requestor
let req: Requestor;
export function inject(requestor: Requestor){
req = requestor;
}
export function useRequestor(){
return req;
}
// 创建一个可以重试的请求
export function createRetryRequestor(maxCount = 5){
const req = useRequestor();
// 进一步配置req
return req;
}
// 创建一个并发请求
export function createParallelRequestor(maxCount = 4){
const req = useRequestor();
// 进一步配置req
return req;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
request-axios-imp代码示意
import { Requestor } from 'request-core'
import axios from 'axios';
const ins = axios.create();
export requestor: XRequestor = {
get(url, options?){
// 使用axios实现
},
// 其他请求方法
}
2
3
4
5
6
7
8
9
10
11
request-bus示意代码
// 为request-core注入requestor的具体实现
import { inject } from 'request-core';
import { requestor } from 'request-axios-imp';
inject(requestor);
2
3
4
这样一来,当将来如果实现改变时,无须对request-core做任何改动,仅需新增实现并改变依赖即可。
比如,将来如果改为使用fetch api完成请求,仅需做以下改动:
新增库request-fetch-imp
import { Requestor } from 'request-core'
export requestor: Requestor = {
get(url, options?){
// 使用fetch实现
},
post(url, data, options?){
// 使用fetch实现
},
// 其他请求方法
}
2
3
4
5
6
7
8
9
10
11
改变request-bus的依赖
- import { requestor } from 'request-axios-imp';
+ import { requestor } from 'request-fetch-imp';
inject(requestor);
2
3
# 请求缓存
请求缓存是指创建一个带有缓存的请求,当没有命中缓存时发送请求并缓存结果,当有缓存时直接返回缓存。
const req = createCacheRequestor();
req.get('/a'); // 请求
req.get('/a'); // 使用缓存
req.get('/b'); // 请求
req.get('/b'); // 使用缓存
2
3
4
5
要实现此功能需要考虑几个核心问题:
请求结果怎么存?存在哪?缓存键是什么?
我们希望用户能够指定缓存方案(内存/持久化),同时也能够指定缓存键。
const req = createCacheRequestor({
key: (config){
// config为某次请求的配置
return config.pathname; // 使用pathname作为缓存键
},
persist: true // 是否开启持久化缓存
});
2
3
4
5
6
7
存储有多种方案,不同的方案能够存储的格式不同、支持的功能不同、使用的API不同、兼容性不同。
为了抹平这种差异,避免将来存储方案变动时对其他代码造成影响,需要设计一个稳定的接口来屏蔽方案间的差异。

export interface CacheStore{
has(key: string): Promise<boolean>;
set<T>(key: string, ...values: T[]): Promise<void>;
get<T>(key: string): Promise<T>;
// 其他字段
}
export function useCacheStore(isPersist): CacheStore{
if(!isPersist){
return createMemoryStore();
}
else{
return createStorageStore();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
缓存何时失效?基于时间还是其他条件?
我们希望用户能够指定缓存如何失效
const req = createCacheRequestor({
duration: 1000 * 60 * 60, // 指示缓存的时间,单位毫秒
isValid(key, config){ // 自定义缓存是否有效,提供该配置后,duration配置失效
// key表示缓存键, config表示此次请求配置
// 返回true表示缓存有效,返回false缓存无效。
},
});
2
3
4
5
6
7
如何实现?
核心逻辑
function createCacheRequestor(cacheOptions){
const options = normalizeOptions(cacheOptions); // 参数归一化
const store = useCacheStore(options.persist); // 使用缓存仓库
const req = useRequestor(); // 获得请求实例
// 对请求进行配置(见后)
return req;
}
2
3
4
5
6
7
// 对请求进行配置
// 注册请求发送前的事件
req.on('beforeRequest', async (config)=>{
const key = options.key(config); // 获得缓存键
const hasKey = await store.has(key); // 是否存在缓存
if(hasKey && options.isValid(key, config)){ // 存在缓存并且缓存有效
// 返回缓存结果
}
})
req.on('responseBody', (config, resp)=>{
const key = options.key(config); // 获得缓存键
store.set(key, resp.toPlain());
})
2
3
4
5
6
7
8
9
10
11
12
13
14
# 请求幂等
幂等性是一个数学概念,常见于抽象代数
$f(n) = 1^n$ 无论n的值是多少,f(n)不变为1
在网络请求中,很多接口都要求幂等性,比如支付,同一订单多次支付和一次支付对用户余额的影响应该是一样的。
要解决这一问题,就必须保证: 要求幂等的请求不能重复提交
这里的关键问题就在于定义什么是重复?
我们可以把重复定义为: 请求方法、请求头、请求体完全一致
因此,我们可以使用hash将它们编码成一个字符串。
function hashRequest(req){
const spark = new SparkMD5();
spark.append(req.url);
for(const [key, value] of req.headers){
spark.append(key);
spark.append(value);
}
spark.append(req.body);
return spark.end();
}
2
3
4
5
6
7
8
9
10
当请求幂等时,直接返回缓存结果即可
在实现上,可以直接利用缓存功能实现
function createIdempotentRequestor(genKey){
return createCacheRequestor({
key: (config) => genKey ?genKey(config) :hashRequest(config),
persist: false
});
}
2
3
4
5
6
# 样板代码
公司的API接口数量庞大并且时常变化,如果request-bus层全部人工处理不仅耗时,而且容易出错。
可以通过一些标准化的工具让整个过程自动化。

接口平台
公司自研了一套接口平台,通过接口平台可以自定义一些字段
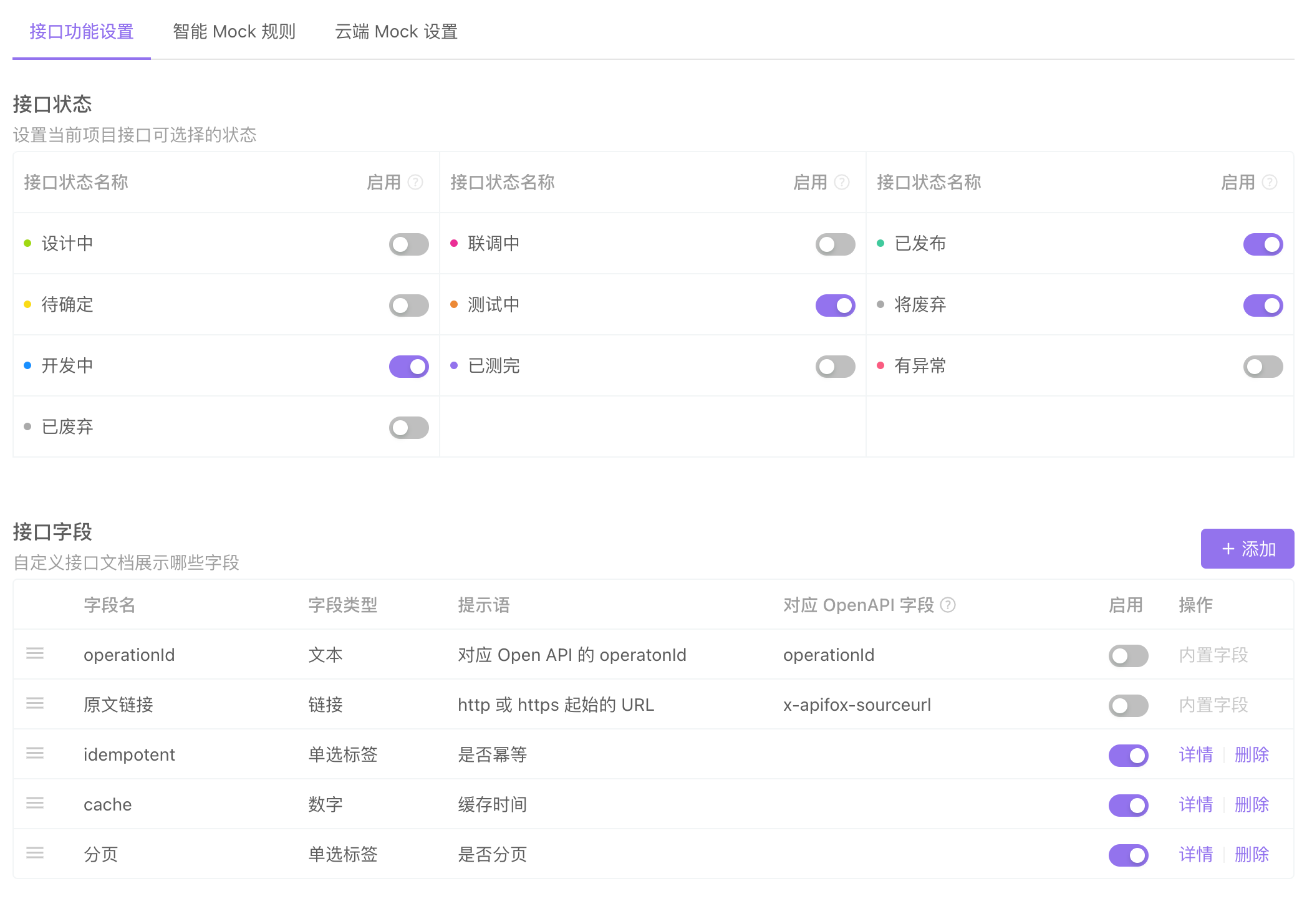
这样一来,制定接口文档时即可设置对应字段
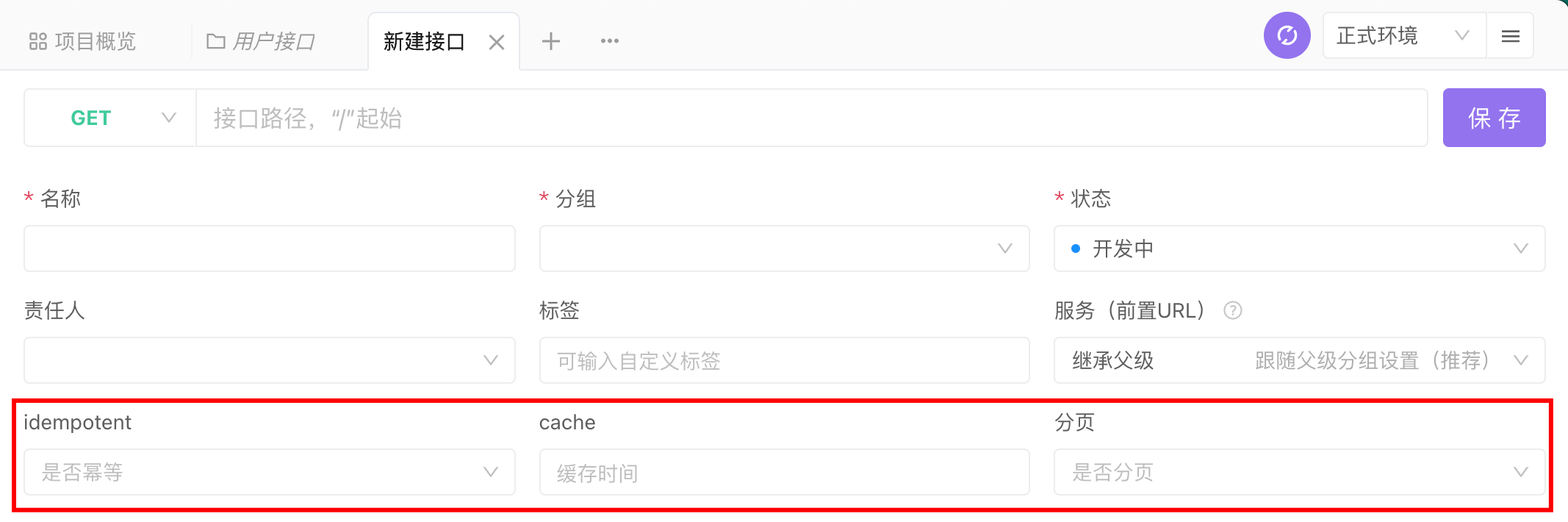
同时,接口平台提供了生成标准格式的API,通过请求API即可生成标准的JSON描述文件
{
"endpoints": {
"article": {
"publishArticle": {
"path": "/api/article",
"description": "发布文章",
"method": "POST",
"auth": true,
"idempotent": true,
"cache": false,
"pager": false,
// 其他字段
},
"getArticles": {
"path": "/api/article",
"description": "获取文章",
"method": "GET",
"auth": false,
"idempotent": false,
"cache": false,
"pager": true,
// 其他字段
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
这样一来,就为自动化生成样板代码提供了可能
样板代码的生成
我们使用node开发了命令行工具request-templet-cli,用于样板代码的生成
上面的json格式生成的样板代码如下:
// request-bus/templet/article.ts
import { createIdempotentRequest } from 'request-core';
/**
* 发布文章
*/
export const publishArticle = (() => {
const req = createIdempotentRequest();
return async (article: Article) => {
return req.post('/api/article', article).then(resp=>resp.json())
}
})();
/**
* 获取文章
*/
export const getArticles = (() => {
return async (page: number, size: number) => {
return req.get('/api/article', {
params:{
page,
size
}
}).then(resp=>resp.json())
}
})();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
补丁
有时候样板代码可能不能满足需求,需要手动进行改动。
我们可以使用打补丁的方式去修改样板代码,做法非常简单。
<见demo>
# 简历和面试
# 简历
项目名: <写你做过的真实项目>
岗位: 中级 / 高级 前端工程师
项目介绍:
介绍你的真实项目
项目职责:
介绍你的项目职责
- 参与项目的通用库开发
项目亮点:
从0到1开发整个请求库,以适配项目开发中遇到的所有请求场景,诸如请求并发、串行、幂等、缓存等。同时包含自动化工具,用于根据接口文档生成请求样板代码。
请求库不仅完全消除了不同框架间重复的请求代码,极大的缩短了接口联调的时间,为业务开发提效30%,同时带来了更高的可维护性。
# 面试
请讲讲你是如何实现请求库的
方案选择
首先我考虑的是实现的必要性。
前端本身存在诸多的请求库,像成熟度比较高的axios,但它们都是一些基础库,没有提供上层功能,比如请求并发、请求重试、请求幂等这些都没有。
另外像一些上层的请求库倒是有这些功能,比如VueRequest,SWR,但它们都和具体的框架绑定了,并且没有提供请求的基础功能,而且它们之间使用风格和功能点都有差异。
更重要的一点是,市面上的公共库不可能提供基于公司内部协议的封装。
所以我不得不考虑重新实现基于公司内部业务的通用请求库。
技术实现
在实现层面,我首先考虑的是请求库的整体结构。
我把请求库分为三层,从下到上依次是请求基础库,负责发送请求的基本功能,然后是请求核心库,负责实现各种上层逻辑,比如并发等等,最上层是请求业务库,负责在代码层面封装公司内部协议。
在结构上,考虑到请求基础库的具体实现方式可能有变动,必须由xhr换成axios或者fetch,为了减少变动对上层代码造成的改动,我应用DIP原则,参考了后端的IOC和DI,让核心库不依赖具体的请求基础库,核心库仅提供TS接口,请求基础库可以基于接口提供不同的实现方式,在业务库注入具体实现即可,这样一来,就彻底隔离了请求的具体实现,将来实现变动后可以轻易的接入。
另外,上层业务库由于深度绑定公司内部的接口文档,而我们项目中的接口数量非常庞大,为了减少开发和维护成本,我用node实现了一个自动化工具,通过解析接口标准文档,自动为每个接口生成请求样板代码,并且考虑到某些样板代码可能不符合实际需要,我制定了一种可以基于样板代码打补丁的开发方式。这样既减少了开发量,同时也保证了灵活度。
落地效果
以上就是大体情况,里面细节还很多就不一一列举了。后续我还在请求库基础上进一步封装了针对各种前端框架的请求库,那都是很薄的一层,比较简单就不详细说了。
整个请求库的落地效果还是很亮眼的,业务开发人员再也无须关心任何的请求,只需调用请求库的业务函数即可,无须关心内部的并发、幂等这些复杂问题,这些事情对业务开发人员完全无感。
整个请求库为公司的业务开发带来30%的效率提升,并依靠自动生成的样板代码,减少了50%的接口联调的时间。