# 大文件上传
# 背景
我们的 SaaS 平台中包含企业资料、会议视频等大文件的上传,如果不作特殊处理,将遇到以下问题:
- 网络中断、程序异常退出等问题导致文件上传失败,从而不得不全部重新上传
- 同一文件被不同用户反复上传,白白占用网络和服务器存储资源
因此,需要一个针对大文件上传的方案来解决上述问题。
# 问题和方案
大文件上传的普遍方案是文件分片上传。
如果把文件上传看做是一个不可分割的事务,那么分片的目标就是把一个耗时的大事务划分为一个一个的小事务。
由于公司使用 BFF 层来承接前端的文件请求,因此需要打通前后端所有跟文件上传的障碍。
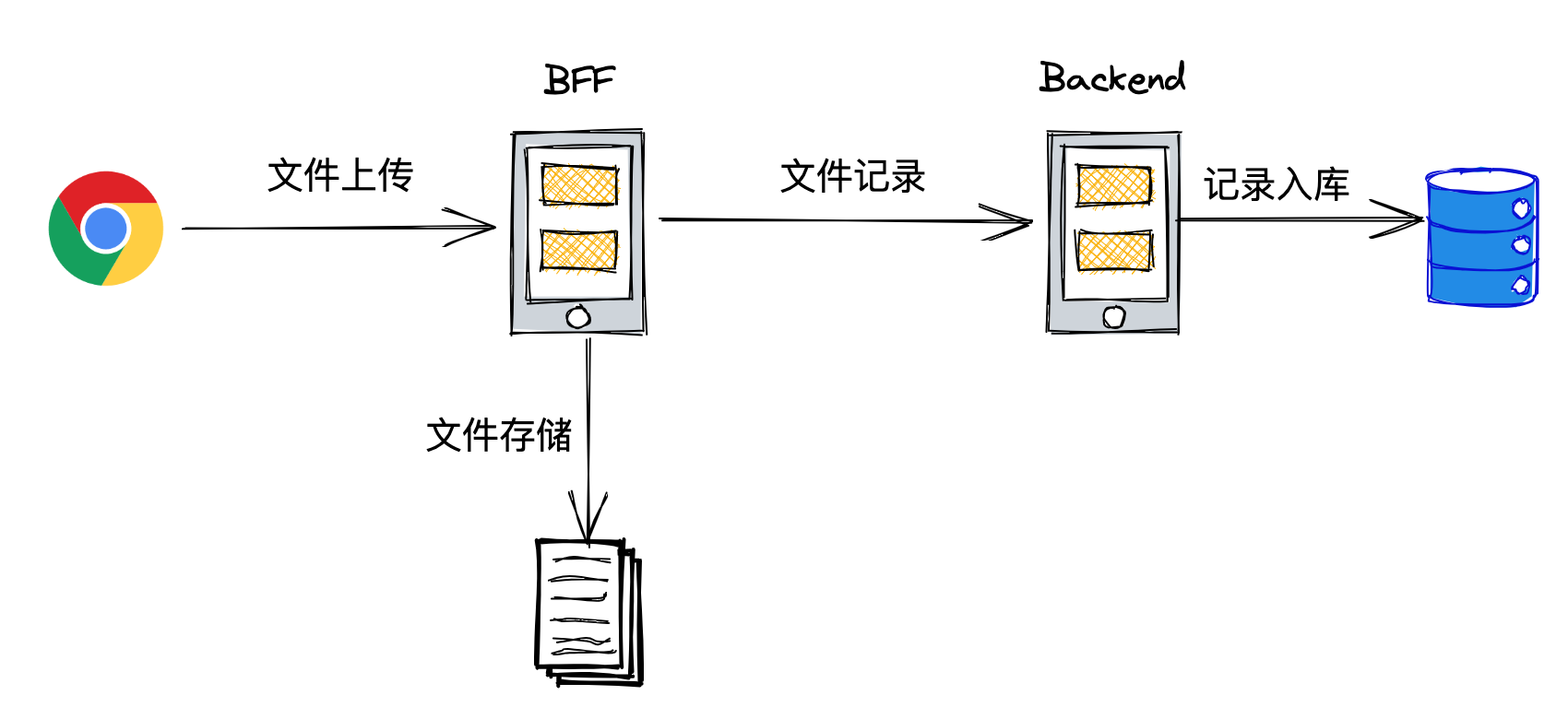
分片上传的主要障碍集中在:
- 如何减少页面阻塞
- 前后端如何协调
- 代码如何组织
- 前端代码中的复杂逻辑
- BFF 代码中的复杂逻辑
下面分开阐述
# 如何减少页面阻塞?
分片上传的一个首要目标就是要尽量避免相同的分片重复上传。服务器必须要能够识别来自各个客户端的各个上传请求中,是否存在与过去分片相同的上传请求。
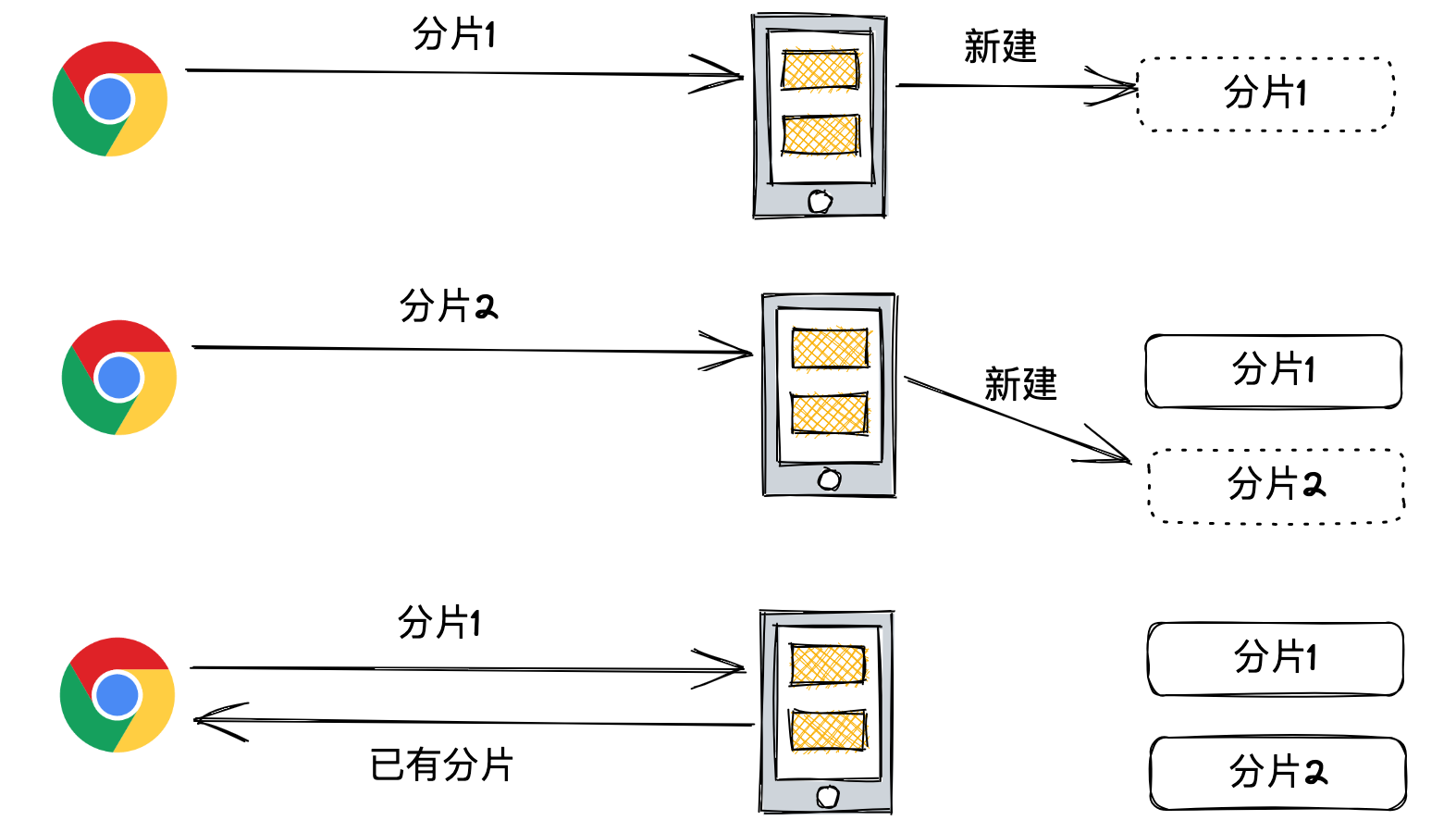
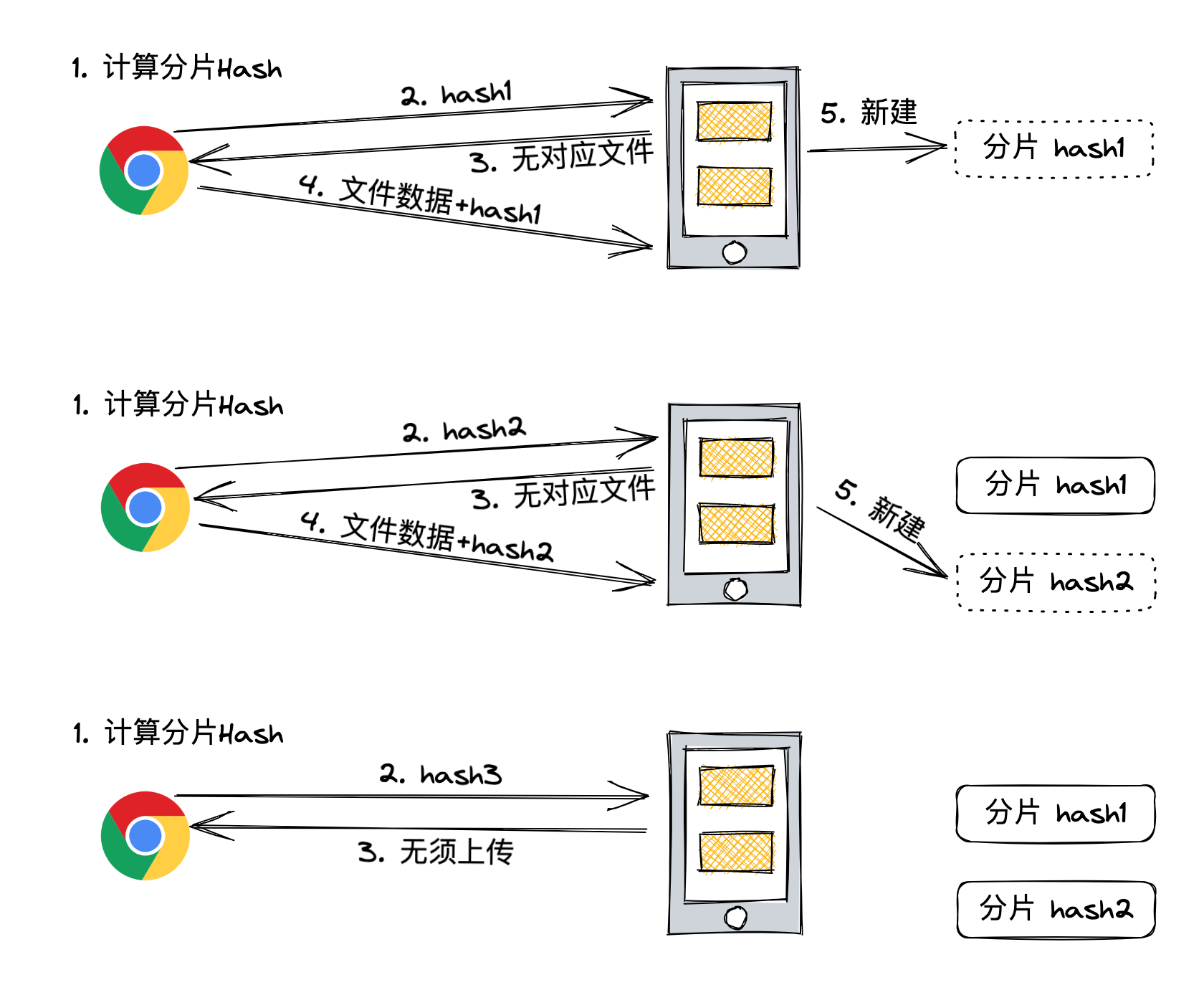
服务器如何识别哪些分片是相同的呢?
首先需要对相同下一个准确的定义: 文件内容一样即为相同。
可是对文件内容进行二进制的对比是一个非常耗时的操作,于是可以选择基于内容的 hash 来进行对比。
hash 是一种算法,可以将任何长度的数据转换为定长的数据,常见的 hash 算法包括 MD5、SHA-1。
本节课使用 MD5 进行 hash 计算,使用第三方库 Spark-MD5 (opens new window)。
不仅针对分片如此,针对整个文件也是如此。
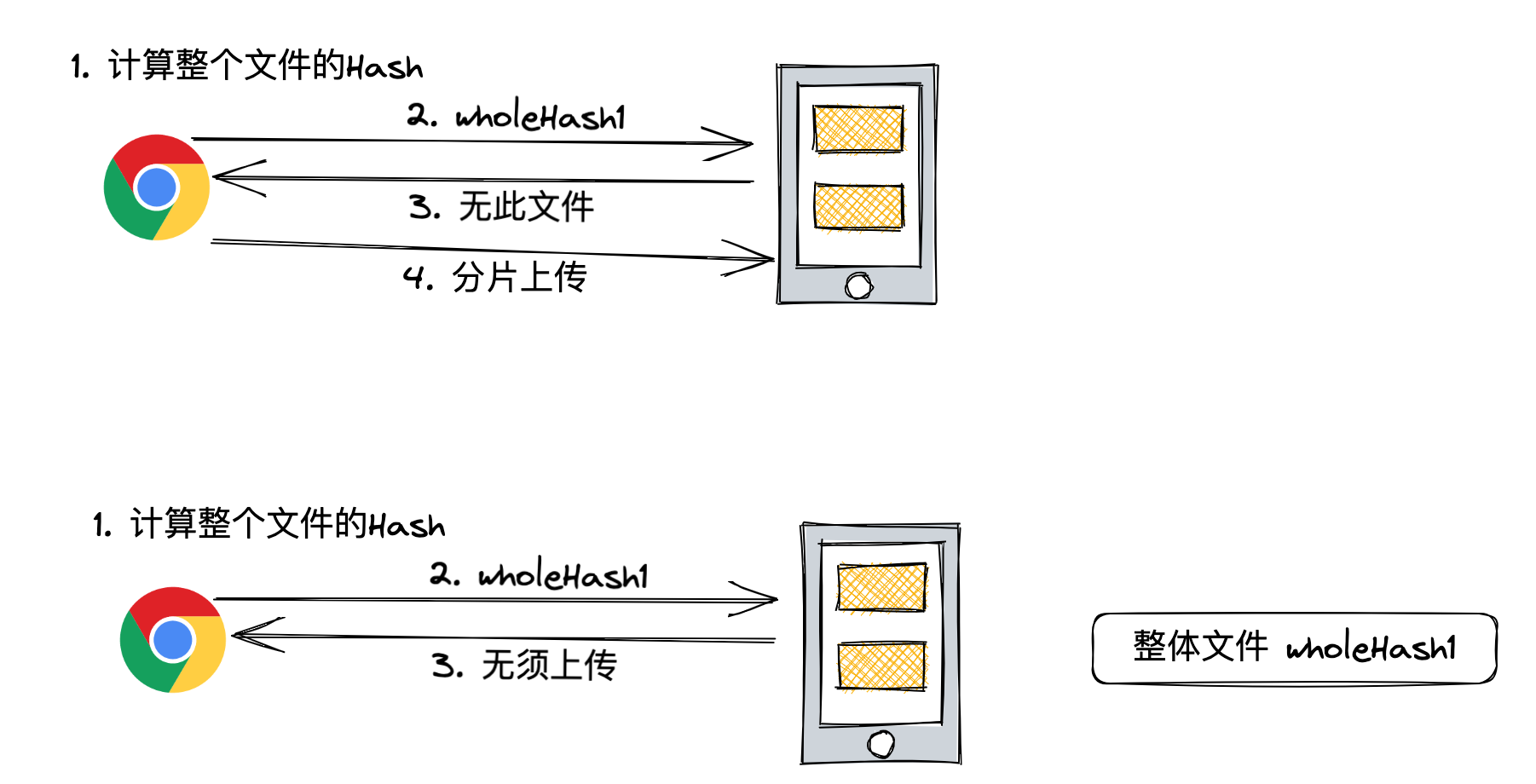
可见,客户端需要承担两件重要的事情:
- 对文件进行分片,并计算每个分片的 hash 值
- 根据所有分片的 hash 值,计算整个文件的 hash 值
而计算 Hash 是一件 CPU 密集型的操作,如果不加处理将会导致长时间阻塞主线程。
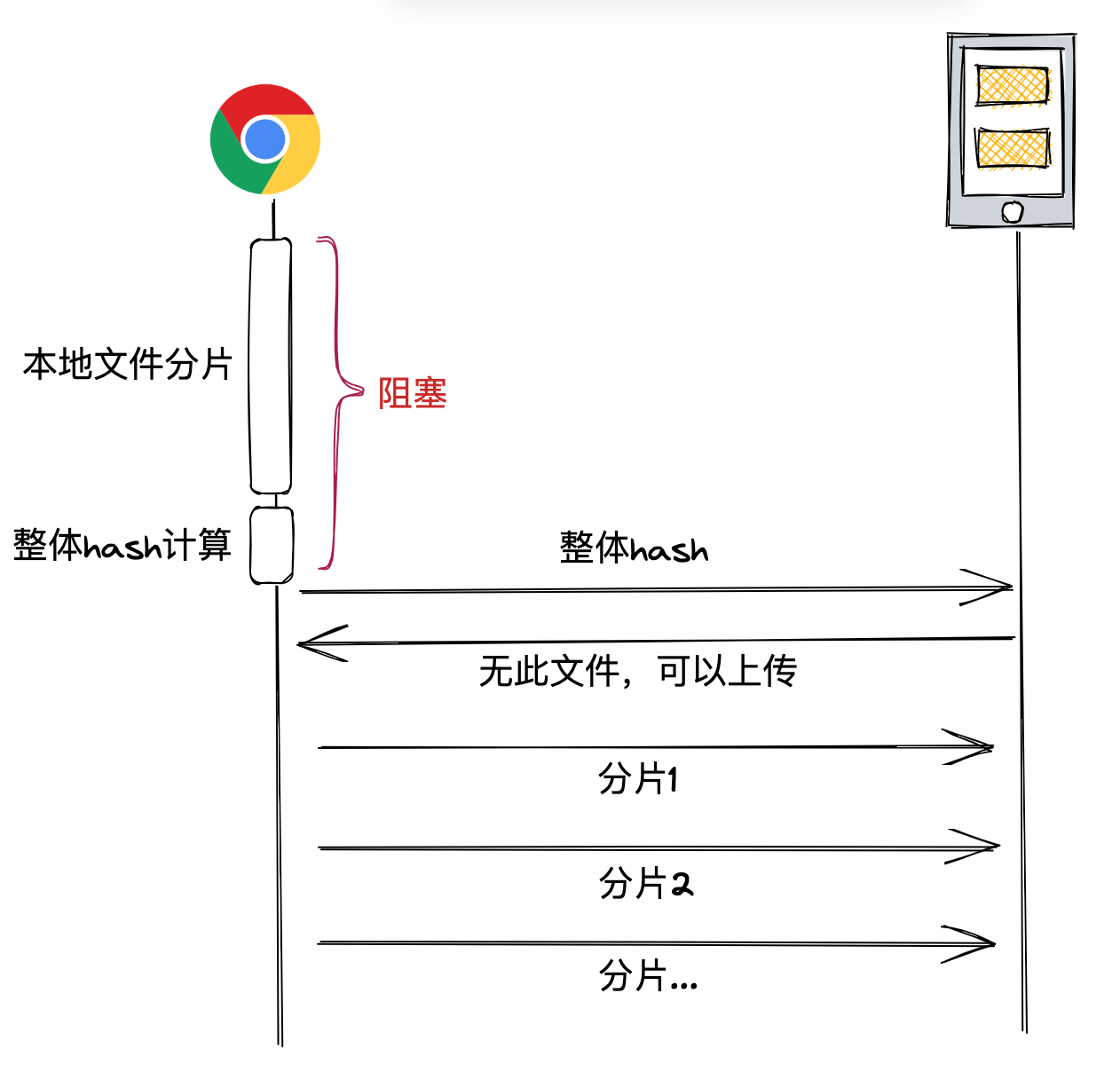
为了解决这个问题,我们可以对大文件上传做一个大胆的假设:绝大部分的文件上传都是新文件上传。
有了这个假设,我们就无须等待整体 hash 的计算结果,直接上传分片即可,同时可以把分片操作使用多线程+异步的方式进行上传处理。
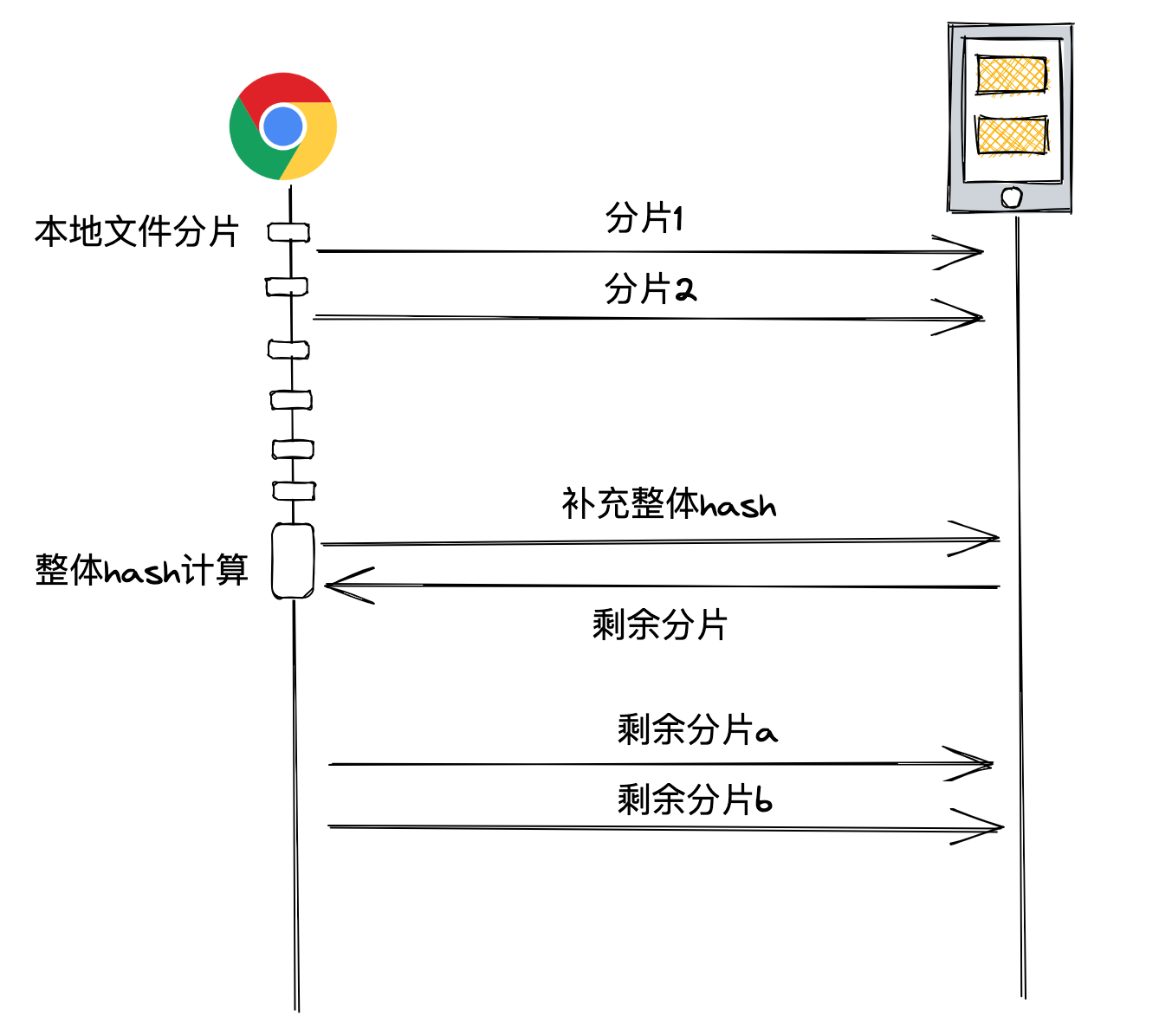
这样做的好处是,页面完全无阻塞,也无须等待整体 hash 即可启动上传,相比于传统方案:
- 对于新文件上传可以缩短整体上传时间,消除页面的阻塞。
- 对于旧文件上传可能会产生一些无效的请求,但这些请求仅传递的是 hash,并不真实上传文件数据,所以对网络和服务器影响很小,加之旧文件上传情况相对较少,所以整体影响可以忽略不计。
# 前后端如何协调?
文件上传涉及到前后端的交互,需要建立一个标准的通信协议,通过协议要能完成下面几件核心交互:
- 创建文件
- hash 校验
- 分片数据上传
- 分片合并
# 创建文件协议
当客户端发送分片到服务器时,需要告知服务器分片属于哪一次文件上传,因此需要一个唯一标识来标识某一次文件上传。
创建文件协议就是用于获取文件上传的唯一标识。

uploadToken: 文件上传的唯一标识chunkSize: 分片大小,单位字节
# hash 校验协议
客户端有时需要校验单个分片或整个文件的 hash,服务器需要告知客户端它们目前的具体情况。
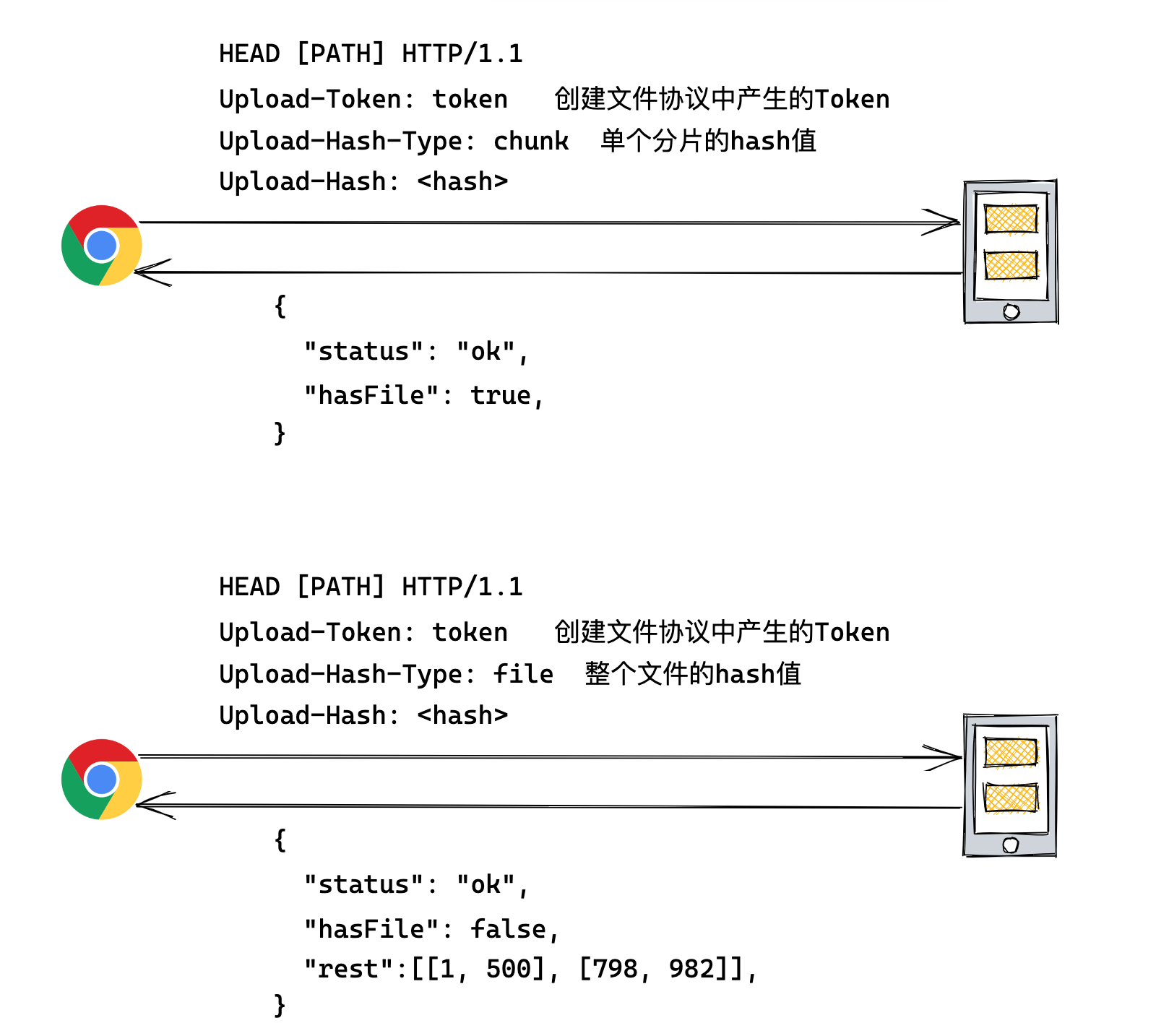
Upload-Hash-Type: 取值chunk或file,分别代表分片 hash 和文件整体 hashUpload-Hash: 分片或文件的具体 hash 值hasFile: 指示服务器是否已经存储了对应的分片或文件rest: 当校验文件 hash 时特有的响应字段, 指示该文件还剩余哪些 hash 没有上传url: 当校验文件 hash 时特有的响应字段, 如果该文件已完成上传出现该字段, 表示文件的请求地址
# 分片数据上传协议
通过此协议,上传具体的文件分片数据

# 分片合并协议
当所有的分片全部上传后,通过此协议请求服务器完成分片合并。

# 代码如何组织?
大文件上传 SDK 的搭建分为三层:
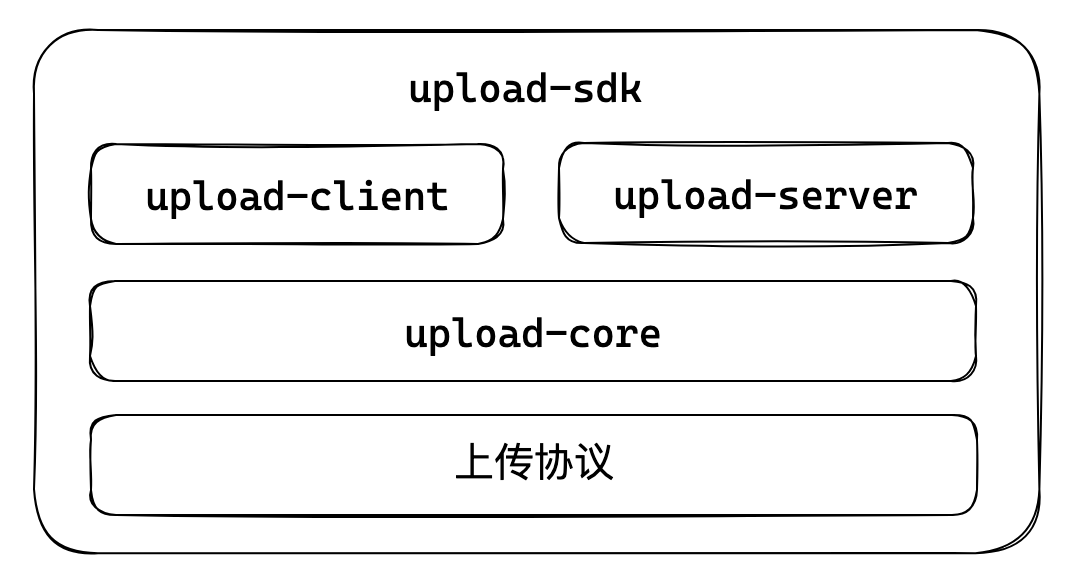
上传协议 约定前后端的通信格式
upload-core 基于协议的 API,提供协议字段的创建、读取、前后端通用工具函数等核心功能
upload-client 应用于客户端的 SDK
upload-server 应用于 BFF 的 SDK
# upload-core 中的通用函数
EventEmitter
统一前后端涉及到的基于各种事件的处理,使用发布订阅模式提供统一的 EventEmitter 类。
- 前端可能出现的各种事件: 上传进度改变事件、上传暂停/恢复事件等等
- 后端可能出现的各种事件: 分片写入完成事件、分片合并完成事件等等
export class EventEmitter<T extends string> {
private events: Map<T, Set<Function>>;
constructor() {
this.events = new Map();
}
on(event: T, listener: Function) {
if (!this.events.has(event)) {
this.events.set(event, new Set());
}
this.events.get(event)!.add(listener);
}
off(event: T, listener: Function) {
if (!this.events.has(event)) {
return;
}
this.events.get(event)!.delete(listener);
}
once(event: T, listener: Function) {
const onceListener = (...args: any[]) => {
listener(...args);
this.off(event, onceListener);
};
this.on(event, onceListener);
}
emit(event: T, ...args: any[]) {
if (!this.events.has(event)) {
return;
}
this.events.get(event)!.forEach((listener) => {
listener(...args);
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
TaskQueue
为支撑前后端的多任务并发执行,提供 TaskQueue 类
- 前端可能的并发执行: 并发请求
- 后端可能的并发执行: 并发的分片 Hash 校验
// 任务构造器
export class Task {
fn: Function; // 任务关联的执行函数
payload?: any; // 任务关联的其他信息
constructor(fn: Function, payload?: any) {
this.fn = fn;
this.payload = payload;
}
// 执行任务
run() {
return this.fn(this.payload);
}
}
// 可并发执行的任务队列
export class TaskQueue extends EventEmitter<"start" | "pause" | "drain"> {
// 待执行的任务
private tasks: Set<Task> = new Set();
// 当前正在执行的任务数
private currentCount = 0;
// 任务状态
private status: "paused" | "running" = "paused";
// 最大并发数
private concurrency: number = 4;
constructor(concurrency: number = 4) {
super();
this.concurrency = concurrency;
}
// 添加任务
add(...tasks: Task[]) {
for (const t of tasks) {
this.tasks.add(t);
}
}
// 添加任务并启动执行
addAndStart(...tasks: Task[]) {
this.add(...tasks);
this.start();
}
// 启动任务
start() {
if (this.status === "running") {
return; // 任务正在进行中,结束
}
if (this.tasks.size === 0) {
// 当前已无任务,触发drain事件
this.emit("drain");
return;
}
// 设置任务状态为running
this.status = "running";
this.emit("start"); // 触发start事件
this.runNext(); // 开始执行下一个任务
}
// 取出第一个任务
private takeHeadTask() {
const task = this.tasks.values().next().value;
if (task) {
this.tasks.delete(task);
}
return task;
}
// 执行下一个任务
private runNext() {
if (this.status !== "running") {
return; // 如果整体的任务状态不是running,结束
}
if (this.currentCount >= this.concurrency) {
// 并发数已满,结束
return;
}
// 取出第一个任务
const task = this.takeHeadTask();
if (!task) {
// 没有任务了
this.status = "paused"; // 暂停执行
this.emit("drain"); // 触发drain事件
return;
}
this.currentCount++; // 当前任务数+1
// 执行任务
Promise.resolve(task.run()).finally(() => {
// 任务执行完成后,当前任务数-1,继续执行下一个任务
this.currentCount--;
this.runNext();
});
}
// 暂停任务
pause() {
this.status = "paused";
this.emit("pause");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
# 前端代码中的复杂问题
前端涉及到两个核心问题:
- 如何对文件分片
- 如何控制请求
# 如何对文件分片?
首先要实现分片对象的处理
// chunk.ts
export interface Chunk {
blob: Blob; // 分片的二进制数据
start: number; // 分片的起始位置
end: number; // 分片的结束位置
hash: string; // 分片的hash值
index: number; // 分片在文件中的索引
}
// 创建一个不带hash的chunk
export function createChunk(
file: File,
index: number,
chunkSize: number,
): Chunk {
const start = index * chunkSize;
const end = Math.min((index + 1) * chunkSize, file.size);
const blob = file.slice(start, end);
return {
blob,
start,
end,
hash: "",
index,
};
}
// 计算chunk的hash值
export function calcChunkHash(chunk: Chunk): Promise<string> {
return new Promise((resolve) => {
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader();
fileReader.onload = (e) => {
spark.append(e.target?.result as ArrayBuffer);
resolve(spark.end());
};
fileReader.readAsArrayBuffer(chunk.blob);
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
接下来,要对整个文件进行分片,分片的方式有很多,比如:
- 普通分片
- 基于多线程的分片
- 基于主线程时间切片的分片(React Fiber)
- 其他分片模式
考虑到通用性,必须要向上层提供不同的分片模式,同时还要允许上层自定义分片模式,因此在设计上,使用基于抽象类的模板模式来完成处理。
// ChunkSplitor.ts
// 分片的相关事件
// chunks: 一部分分片产生了
// wholeHash: 整个文件的hash计算完成
// drain: 所有分片处理完成
export type ChunkSplitorEvents = "chunks" | "wholeHash" | "drain";
export abstract class ChunkSplitor extends EventEmitter<ChunkSplitorEvents> {
protected chunkSize: number; // 分片大小(单位字节)
protected file: File; // 待分片的文件
protected hash?: string; // 整个文件的hash
protected chunks: Chunk[]; // 分片列表
private handleChunkCount = 0; // 已计算hash的分片数量
private spark = new SparkMD5(); // 计算hash的工具
private hasSplited = false; // 是否已经分片
constructor(file: File, chunkSize: number = 1024 * 1024 * 5) {
super();
this.file = file;
this.chunkSize = chunkSize;
// 获取分片数组
const chunkCount = Math.ceil(this.file.size / this.chunkSize);
this.chunks = new Array(chunkCount)
.fill(0)
.map((_, index) => createChunk(this.file, index, this.chunkSize));
}
split() {
if (this.hasSplited) {
return;
}
this.hasSplited = true;
const emitter = new EventEmitter<"chunks">();
const chunksHanlder = (chunks: Chunk[]) => {
this.emit("chunks", chunks);
chunks.forEach((chunk) => {
this.spark.append(chunk.hash);
});
this.handleChunkCount += chunks.length;
if (this.handleChunkCount === this.chunks.length) {
// 计算完成
emitter.off("chunks", chunksHanlder);
this.emit("wholeHash", this.spark.end());
this.spark.destroy();
this.emit("drain");
}
};
emitter.on("chunks", chunksHanlder);
this.calcHash(this.chunks, emitter);
}
// 计算每一个分片的hash
abstract calcHash(chunks: Chunk[], emitter: EventEmitter<"chunks">): void;
// 分片完成后一些需要销毁的工作
abstract dispose(): void;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
基于此抽象类,即可实现多种形式的分片模式,每种模式只需要继承ChunkSplitor,实现计算分片的 hash 即可。
比如,基于多线程的分片类可以非常简单的实现:
// MutilThreadSplitor.ts
export class MultiThreadSplitor extends ChunkSplitor {
private workers: Worker[] = new Array(navigator.hardwareConcurrency || 4)
.fill(0)
.map(
() =>
new Worker(new URL("./SplitWorker.ts", import.meta.url), {
type: "module",
}),
);
calcHash(chunks: Chunk[], emitter: EventEmitter<"chunks">): void {
const workerSize = Math.ceil(chunks.length / this.workers.length);
for (let i = 0; i < this.workers.length; i++) {
const worker = this.workers[i];
const start = i * workerSize;
const end = Math.min((i + 1) * workerSize, chunks.length);
const workerChunks = chunks.slice(start, end);
worker.postMessage(workerChunks);
worker.onmessage = (e) => {
emitter.emit("chunks", e.data);
};
}
}
dispose(): void {
this.workers.forEach((worker) => worker.terminate());
}
}
// SplitWorker.ts
onmessage = function (e) {
const chunks = e.data as Chunk[];
for (const chunk of chunks) {
calcChunkHash(chunk).then((hash) => {
chunk.hash = hash;
postMessage([chunk]);
});
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 如何控制请求?
对请求的控制涉及到多个方面的问题:
如何充分利用带宽 分片上传中涉及到大量的请求发送,这些请求既不能一起发送造成网络阻塞,也不能依次发送浪费带宽资源,因此需要有请求并发控制的机制。 方案: 利用基础库的 TaskQueue 实现并发控制
如何与上层请求库解耦
考虑到通用性,上层应用可能会使用各种请求库来发送请求,因此前端 SDK 不能绑定任何的请求库。 方案: 这里使用策略模式对请求库解耦。
这个类比较复杂,下面贴出核心代码结构
请求策略
// 请求策略
export interface RequestStrategy {
// 文件创建请求,返回token
createFile(file: File): Promise<string>;
// 分片上传请求
uploadChunk(chunk: Chunk): Promise<void>;
// 文件合并请求,返回文件url
mergeFile(token: string): Promise<string>;
// hash校验请求
patchHash<T extends "file" | "chunk">(
token: string,
hash: string,
type: T,
): Promise<
T extends "file"
? { hasFile: boolean }
: { hasFile: boolean; rest: number[]; url: string }
>;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
请求控制
export class UploadController {
private requestStrategy: RequestStrategy; // 请求策略,没有传递则使用默认策略
private splitStrategy: ChunkSplitor; // 分片策略,没有传递则默认多线程分片
private taskQueue: TaskQueue; // 任务队列
// 其他属性略
// 初始化
async init() {
// 获取文件token
this.token = await this.requestStrategy.createFile(this.file);
// 分片事件监听
this.splitStrategy.on("chunks", this.handleChunks.bind(this));
this.splitStrategy.on("wholeHash", this.handleWholeHash.bind(this));
}
// 分片事件处理
private handleChunks(chunks: Chunk[]) {
// 分片上传任务加入队列
chunks.forEach((chunk) => {
this.taskQueue.addAndStart(new Task(this.uploadChunk.bind(this), chunk));
});
}
async uploadChunk(chunk: Chunk) {
// hash校验
const resp = await this.requestStrategy.patchHash(
this.token,
chunk.hash,
"chunk",
);
if (resp.hasFile) {
// 文件已存在
return;
}
// 分片上传
await this.requestStrategy.uploadChunk(chunk, this.uploadEmitter);
}
// 整体hash事件处理
private async handleWholeHash(hash: string) {
// hash校验
const resp = await this.requestStrategy.patchHash(this.token, hash, "file");
if (resp.hasFile) {
// 文件已存在
this.emit("end", resp.url);
return;
}
// 根据resp.rest重新编排后续任务
// ...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 后端代码中的复杂问题
相对于客户端而言,服务器面临着更大的挑战。
# 如何隔离不同的文件上传?
在创建文件协议中,服务器使用 uuid + jwt 生成一个不可篡改的唯一编码,用于标识不同的文件上传。
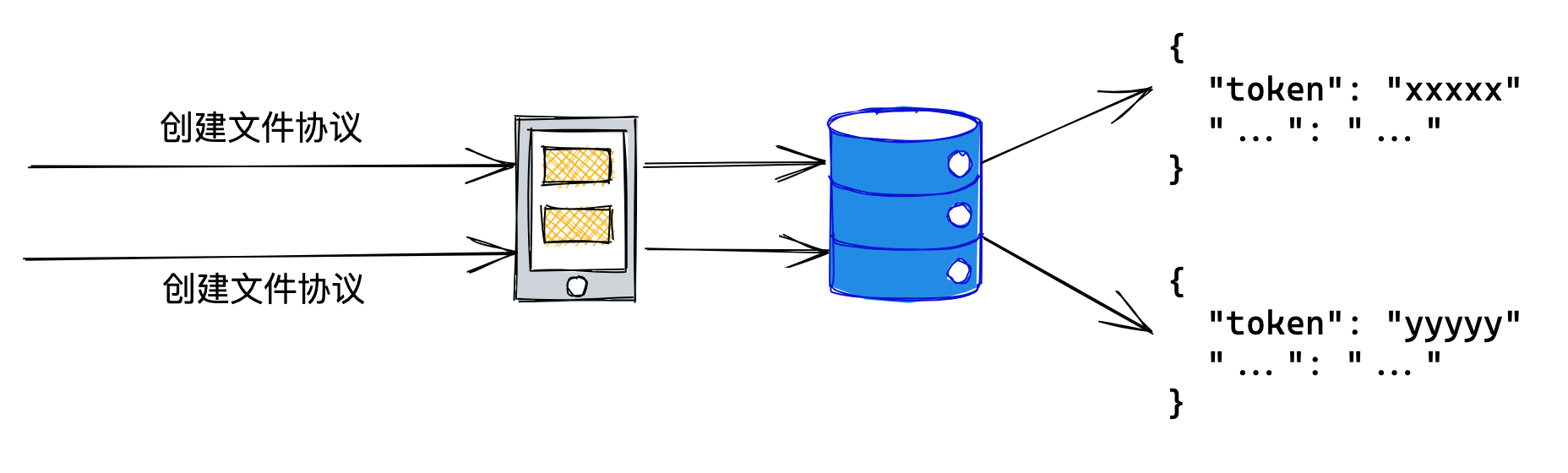
# 如何保证分片不重复?
这里的重复是指:
- 不保存重复分片
- 不上传重复分片
这就要求分片跨文件唯一,并且永不删除
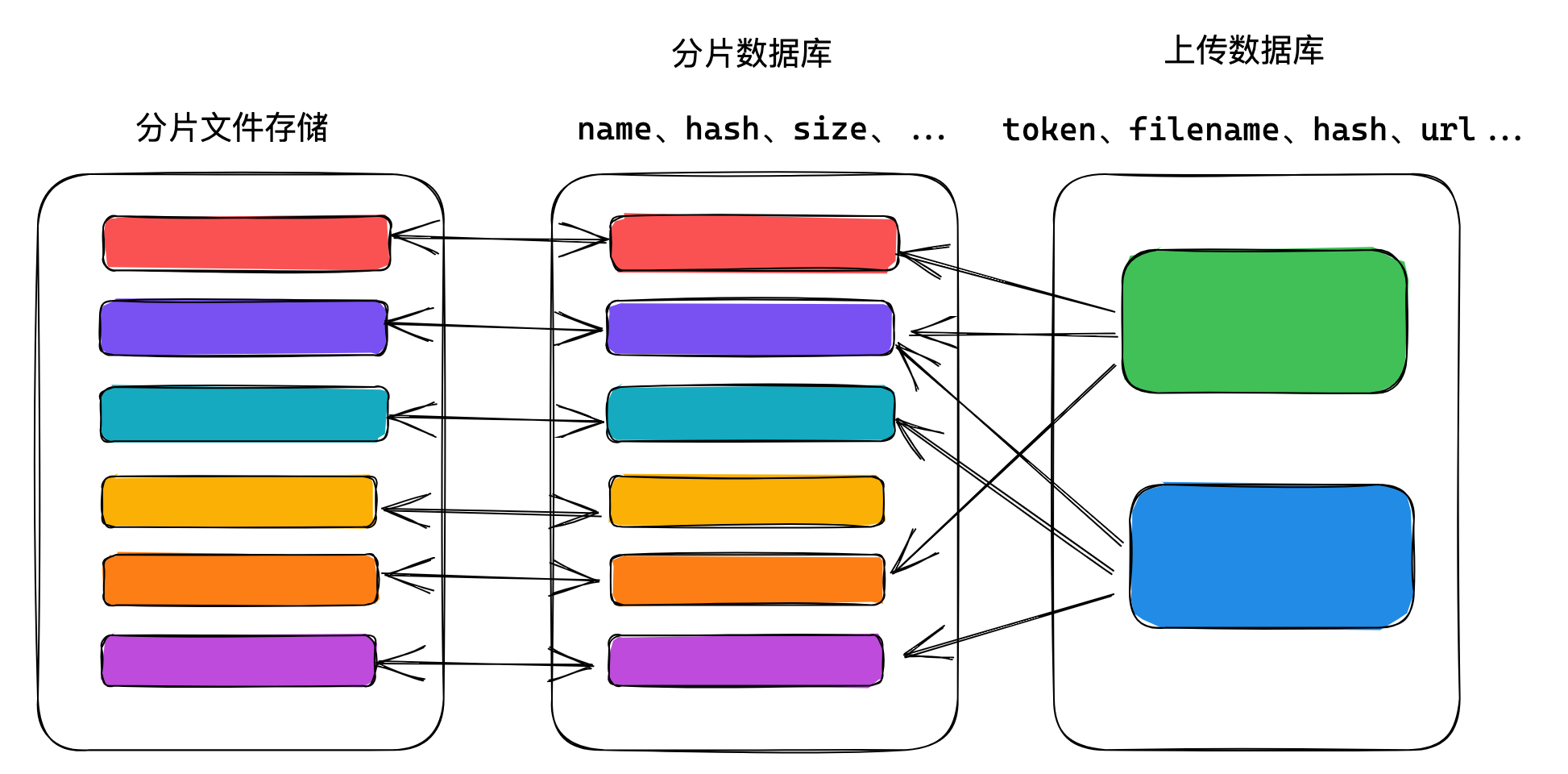
也就是说: 服务器并不保存合并之后的文件,仅记录文件中的分片顺序
# 合并分片到底做什么?
合并会造成很多问题,最主要的是:
- 极其耗时
- 数据冗余
所以服务器并不发生真正的合并,而是在数据库中记录文件中包含的分片。
因此,合并操作时,服务器仅做简单的处理:
- 校验文件大小
- 校验文件 hash
- 标记文件状态
- 生成文件访问地址
- ...
以上操作效率极高
# 访问文件怎么办?
由于服务器并未发生真正的文件合并,当后续请求该文件时,服务器需要动态处理,具体做法是:
- 服务器收到对文件的请求,并在数据库中找到了对应的文件
- 服务器读取文件的所有分片 ID,依次找到对应的分片文件
- 服务器利用 TaskQueue 的并发控制能力,逐步产生文件读取流,并利用管道直接输出到网络 I/O
# 简历和面试
# 简历
项目名: <写你做过的真实项目>
岗位: 中级 / 高级 前端工程师
项目介绍:
介绍你的真实项目
项目职责:
介绍你的项目职责
- 参与项目的通用库开发
项目亮点:
从 0 到 1 开发整个 upload-sdk,该 SDK 为所有文件上传特别是大文件上传的场景提供前后端的支撑,统一了所有文件上传的开发方式,完成了从底层协议、到工具类、到前端组件、再到后端中间件的开发。
在实现层面,为保证使用的灵活性,利用多种设计模式完成了 SDK 和上层应用的完全解耦,并对服务器的存储结构进行了精细的设计,保证了文件存储和传输的唯一性。
# 面试
请讲讲你是如何实现大文件上传的
方案选择
大文件上传的普遍性方案是文件分片,文件分片其实就是把整个文件上传的大事务打散为一个一个分片上传的小事务,从而降低上传失败的风险。
整个大文件上传的实现涉及到诸多的技术细节。
比如底层协议标准如何制定,协议标准决定了前后端如何交互,也就决定了前后端代码如何开发。
除了协议之外,还涉及到前端如何进行并发控制,如何高效的分片,以及涉及到后端如何存储分片,如何高效合并分片,如何保证分片的唯一性等等等等。
诸多的问题吧,市面上没有形成统一的解决方案,虽然公有云上的 OSS 有各自的实现方案,但考虑到我们的产品可能会部署到客户的私有云上,所以最稳妥的办法还是自行实现整个大文件上传。
技术实现
我首先设计的是整个上传流程。
传统的大文件上传都是在客户端先完成所有的分片,然后计算每个分片和完整的文件 hash,再使用 hash 和服务器换取当前文件的信息。
由于 hash 的计算是 CPU 密集型的操作,这样一来就会导致长时间的客户端阻塞,虽然可以使用 Web Worker 来加速 hash 的计算,但经过我的测试,即便是使用了多线程,某些超大文件比如上了 10 个 G 的文件,在配置不太好的客户机上计算时长可以超过 30 秒,这是无法接受的。
因此,我对上传流程进行了优化,我假定大部分文件上传都是一个新文件上传,于是在流程上,我允许用户在获得文件完整 hash 之前直接上传分片,这样一来,几乎可以做到零延时的上传,等到文件整体 hash 计算出来之后,再向服务器补充 hash 数据。
基于这样的流程,于是我设计了一套标准化的文件上传协议
协议主要包含四个通信标准:
- 创建文件协议: 前端使用 HEAD 请求向服务器提交文件基本信息,换取上传唯一 token,后续的请求必须携带此 token
- hash 校验协议: 前端把某个分片 hash 或者是整个文件 hash 发送给服务器,得到分片和文件的状态信息
- 分片上传协议: 前端将分片的二进制数据发送到服务器存储
- 分片合并协议: 前端提示服务器可以完成分片合并了
设计好协议后,接下来就需要落实到代码的实现上
在前端部分主要问题集中在两块: 如何分片 和 如何控制请求流程
首先是如何分片,考虑到不同的场景可能选择不同的分片模式,比如多线程分片,比如基于时间切片(类似于 React Fiber)的分片,甚至是由上层应用自行定义的分片模式。
于是在实现分片逻辑时,我使用了模版模式,利用 TS 的抽象类定义好分片的整体流程,具体的子类仅需实现分片 hash 计算即可,这样一来就可以保持极高的灵活度。
在请求流程控制层面,由于有诸多请求需要发送,因此我开发了一套并发请求控制类以充分的利用网络带宽。
另外,由于请求过程中需要向上层抛出各种钩子,比如进度的变化,请求状态的变化等等,对这一块,我使用了发布订阅模式编写了通用的 EventEmitter 类,这样可以在请求过程中抛出各种事件,上层应用通过监听事件完成处理。
当然整个系统复杂度最高的还是在后端
由于我们这个项目有 BFF 层,需要在 BFF 层完成文件处理,因此我还需要针对服务器编写相应代码。
服务器最大的挑战就是如何保证每个分片的唯一性,这种唯一性即包含存储的唯一性,也包含传输的唯一性。
存储的唯一性保证了分片不会重复保存,避免了数据的冗余。
传输的唯一性保证了分片不会重复上传,避免了通信的冗余。
要保证分片不会重复保存,就必须让分片和文件解耦,分片是分片,文件是文件,分片独立保存,不从属于任何文件,文件独立记录,按照顺序依次指向不同分片,这样一来,哪怕出现两个不同文件拥有相同分片的场景,也不会在服务器出现重复存储的问题,因为分片是独立于文件的。
而要保证分片不会重复上传,就必须保证分片永不删除,如果在合并文件后删除了分片,就会导致下一次有相同分片上传时服务器找不到对应的分片文件,就必须重复上传,因此分片永不删除。
最后就是合并分片的逻辑,我考虑到如果真正的把分片文件合并成一个大文件,大文件的所有数据实际上都是冗余的,而且整个合并过程极其耗时,因此我做了这样的处理。
当收到合并请求时,服务器其实仅仅做一些简单的校验即可,比如文件大小、分片数量等校验,而不进行真正的合并,仅在数据库 mongodb 中更新该文件的状态并生成文件访问的 url 地址即可。
等到用户真正访问文件时,我根据数据库中对应文件的分片记录,使用文件流依次读取分片数据,用流管道直接响应给客户端即可。
这样一来整个合并效率和文件访问效率都极高,同时服务器的存储不会有任何冗余。
以上,就是我整个上传 SDK 的实现思路,其他还有很多细节,但大致上就是这样。