# 首屏优化
# 背景
公司的产品面向的是企业用户,大部分企业用户会选择对产品进行私有化部署。
企业对产品的需求是差异化的,因此公司研发了一套低码平台方便客户对产品进行差异化定制。
客户通过低码平台的定制会产生 JS 文件,这些 JS 文件会在运行时加载。

大量客户反馈首屏等待时间过长的问题,需要制定针对性的优化策略解决问题。
而要针对性的优化必须要先弄清楚目前的性能热点在哪里,因此,我们将整个优化过程分为三步:
- 问题的收集与分析
- 措施的制定与实施
- 方案的部署与反馈
以上三步可反复轮询,直到问题解决。
# 问题的收集与分析
这一步的目标是要准确的找到客户侧的问题究竟在哪,找不到问题就无法针对性的制定优化措施。
而要找到问题并不容易,根据过往经验,大系统的优化问题定位往往需要几个环节的反复进行。

可是问题发生在客户侧,而客户侧的系统不直接暴露到公网,因此收集问题的环节就非常麻烦。
因此,我们搭建了一套客户侧数据上报的流程,让客户可以安全的把性能数据推送到我们的数据中心。

制定这套流程的初衷,不仅是为了方便收集目前特定用户的性能问题,更重要的是可以收集任何客户反馈的任何问题。
要落实这一系列流程,需要在技术面提供多方面的支持:
- 服务监控系统的更改(前端、后端)
- 数据脱敏(大数据)
- 数据展示(前端)
- 问题实验室(前端、BFF)
最终,经过几轮测试,问题被清晰的定位:
- HTTP1.1 协议效率低下的问题
- 队头阻塞
- 头部臃肿
- 大量的 JS 代码重复
- 大量 JS 代码无差别加载
- 大量的 API 网络请求
# 措施的制定与实施
# 针对 HTTP1.1 的优化措施
队头阻塞问题


针对这一问题,没有别的办法,只能多开域名来解决。
浏览器针对同一域名可以支持最多 6 个 TCP 并发连接,超越这个数字后将发生队头阻塞


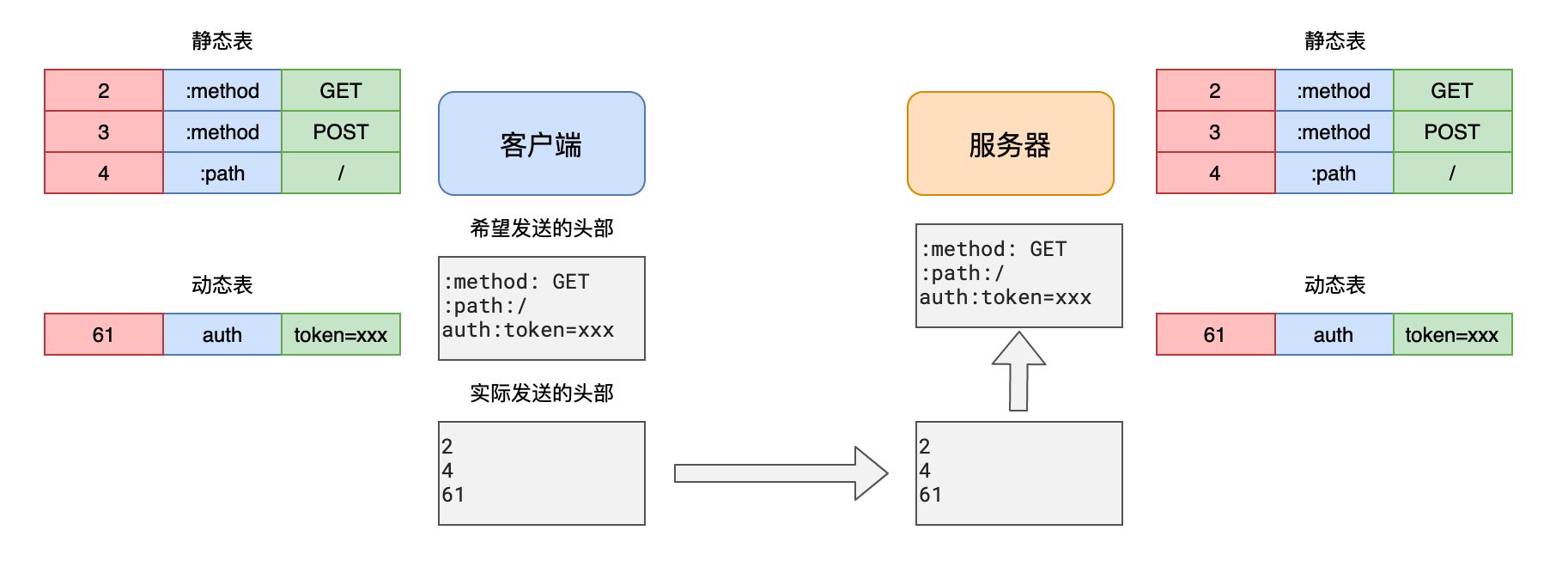
头部臃肿
由于 HTTP1.1 不支持头部压缩,而发送的请求中包含大量的自定义头部,于是我们借鉴了 HTTP2 的头部压缩方式,对自定义头部进行了压缩处理。
# 针对重复代码的优化措施
客户侧会产生巨量的差异化 JS 文件,每个 JS 文件的产生逻辑非常简单:

结果就是客户侧保存了大量 JS 代码文件,并且代码文件中出现了大量重复代码。
// g-d8a65e.js
export default {
formItems: [
{
// 其他差异配置,
init(){
// 代码段a
// 其他差异代码段
},
focus(){
// 代码段a
// 其他差异代码段
}
}
]
}
// g-e218fa.js
export default {
formItems: [
{
// 其他差异配置,
validate(){
// 代码段a
// 其他差异代码段
},
blur(){
// 代码段a
// 其他差异代码段
}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
比较容易想到的解决办法,是把那些有可能出现差异的代码提取到公共代码中。

这种方案除了逻辑简单,根本无法实施,主要原因是:
- 很难知道客户侧会产生哪些重复代码
- 如果把所有可能都枚举到公共代码中,会产生大量的无效代码
因此,对重复代码的提取必须动态完成。

这里面有两个关键问题:
- 如何找到代码中的重复?
- 何时提重?
# 如何找到重复?
考虑下面两段代码,如何找到重复?
// 代码片段1
const selectSource = "department";
const source = getData(selectSource);
bindSelectSource({
source,
label: (s) => `${s.name}`,
value: (s) => `${s.id}`,
});
// 代码片段2
const selectSource = "task";
const source = getData(selectSource);
bindSelectSource({
source,
label: (s) => `${s.title}`,
value: (s) => `${s.id}`,
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
通过 AST 分析,可以得到两棵树

我们的目标是:找出两棵树连续的相同结构的节点,将它们提取成函数,同时把相同结构中的不同点提取为函数参数。
大致思路是:
- 计算每个节点的结构 hash
// 变量声明节点的hash求值
class VariableDeclarationNode {
// ...省略其他代码
hash() {
md5.append(this.kind); // const、var、let
md5.append(this.name); // 变量名
md5.append(this.init.type); // 初始值类型: 字面量、表达式、变量
return md5.end(); // 得到hash
}
}
2
3
4
5
6
7
8
9
10
11
- 将 AST 树信息入库(含 hash 结果)
库中的信息大致如下:
[
{
"filename": "1.js",
"struct": [
{
"hash": ".....",
"children": [
{ "hash": "....", "children": [] },
{ "hash": "....", "children": [] }
]
},
{
"hash": ".....",
"children": [
{ "hash": "....", "children": [] },
{ "hash": "....", "children": [] }
]
}
]
},
{
"filename": "2.js",
"struct": [
{
"hash": ".....",
"children": [
{ "hash": "....", "children": [] },
{ "hash": "....", "children": [] }
]
},
{
"hash": ".....",
"children": [
{ "hash": "....", "children": [] },
{ "hash": "....", "children": [] }
]
}
]
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
- 寻找库中出现的连续的、hash 一致的节点进行提重。
- 将差异点提取为参数
最终提重的结果如下:
// repeating.js
// 自动提重后的代码
function rp_2d4ef(p1, p2) {
const selectSource = p1;
const source = getData(selectSource);
bindSelectSource({
source,
label: (s) => `${s[p2]}`,
value: (s) => `${s.id}`,
});
}
2
3
4
5
6
7
8
9
10
11
然后代码片段被修改为:
// 代码片段1
rp_2d4ef("department", "name");
// 代码片段2
rp_2d4ef("task", "title");
2
3
4
# 何时提重?
为了保证效率,提重可以异步延时执行,也可以开启计划任务在服务器空闲时执行,也可以管理员手动执行。
# 针对无差别加载的优化措施
过去,用户侧自定义产生的差异 JS 都是在首屏全部加载的,实际上,很多 JS 并不需要在当前页面运行。
因此,需要对这些 JS 进行差别化加载,视口内需要的先加载,不需要的延迟加载。
这就需要做到两件事:
- 定义每个功能页视口内组件
- 标识每个 JS 文件对应到哪个组件(已有功能)
此时很容易完成,不再详细阐述。
# 针对大量 API 网络请求的优化措施
大量的首屏请求均来自自动化生成的差异代码,其中包含大量的 GET 重复请求。
我们针对性的加入了短时缓存,让相同的请求走缓存通道。
// 自动生成的代码
const data = await getSelectSource("department");
// 修改为
const data = await withCache(getSelectSource, "department");
2
3
4
5
let map = new Map();
function withCache(fn, ...args) {
if (!map) {
return fn(...args);
}
let caches = map.get(fn);
if (!caches) {
// 无缓存,初始化
map.set(fn, (caches = []));
}
let cache = caches.find((c) => isSameArgs(args, c.args)); // 按参数查找缓存
if (!cache) {
// 无缓存,初始化
caches.push(
(cache = {
args,
value: fn(...args),
}),
);
}
return cache;
}
const CACHE_DURATION = 5000;
setTimeout(() => {
map = null;
}, CACHE_DURATION);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 简历和面试
# 简历
项目名: <写你做过的真实项目>
岗位: 中级 / 高级 前端工程师 / 前端架构师
项目介绍:
介绍你的真实项目
项目职责:
介绍你的项目职责
- 负责/参与项目优化方案的制定和实施
项目亮点:
针对客户反馈的首屏慢问题制定了详细的优化策略并完整参与了优化措施的落地。
通过数据埋点收集和定位性能问题,通过本地实验室复现问题。针对问题制定了具体的优化措施,包括解决了 HTTP1.1 的队头阻塞和头部无压缩的问题,以及开发了自动化工具完成自动代码提重从而压缩包体积等诸多手段。
经过优化后的代码 LCP 时间降低了 80%,同时提供了一套完整标准的工单流程。
# 面试
请讲讲你是如何首屏优化的
策略的制定
无论是做哪一种优化,都需要经过三个步骤:定位问题、解决问题、测试反馈。
很多时候都是在这三个步骤间反复轮询。
而我们项目的难点在于我们的产品很多是私有化部署,并且用户可以通过低码平台实现产品的高度定制。也就是说我们无法知晓客户定制了哪些内容,由定制产生了多少 JS 文件,无法复现客户的运行环境,无法复现客户的问题。
所以我首先是制定了一套完整的工单申报流程,为每个客户提出的问题发起工单,然后在本地开启工单的代码分支,在分支里面针对性的加入埋点代码,然后推送代码给用户。
用户一端收集的信息经过数据脱敏后上报到我们的数据中心,我这边根据数据最终定位问题。
下面我挑一两个问题说吧。
技术实现
我们当时遇到的一个比较大的问题是 HTTP1.1 的效率问题,因为我们的客户有些浏览器是不支持 HTTP2 的,而首屏加载的资源量数量非常多,受我们架构的影响又很难合并它们,所以会遇到 HTTP1.1 的队头阻塞和头部压缩的问题。
针对队头阻塞,我使用了多域名的方式解决,这是常规手段,没多少可说的。而头部压缩这一块,我是借鉴了 HTTP2 的做法,在客户端和服务器分别建立静态表和动态表,把所有的自定义头部压缩成了一个,压缩比最高可以达到 90,这是非常惊人的。
另外除了网络这一块,还遇到一个比较棘手的问题就是重复代码。客户那边很多代码是他们通过低码平台自动生成的,有些定制度比较高的客户可能生成了好几百个 JS,这些 JS 文件中存在大量重复的代码,从而增加了整体的传输体积。
所以我开发了一套任务,它可以自动嗅探到多个 JS 文件中的重复代码,并把他们提取到一个公共 JS 中形成一个一个的函数,把差异化的地方自动提取为参数,然后自动修改原始 JS 文件的相应位置,把它们变成一个一个的函数调用。
这件事说起来简单,实际开发起来其实是非常复杂的,它涉及到抽象语法树分析、树结构对比从而发现重复和提取重复、hash 运算和数据库存储等一系列的事情,因为这件事是在 BFF 层完成的,所以也是由我们前端处理的。
其他的优化还有很多,有些简单有些麻烦,但最棘手、我印象最深的就是上面两点。