# 实现响应式系统
# 核心要素
要实现一个响应式系统,最为核心的有两个部分:
- 监听数据的读写
- 关联数据和函数
只要把这两个部分完成了,那么整个响应式系统也就基本成型了。
# 监听数据读写
- 数据:在 JS 中,能够拦截读写的方式,要么 Object.defineProperty,要么就是 Proxy,这两个方法针对的目标是对象,因此我们这里考虑对对象类型进行监听
- 读写:虽然说是监听读写,但是细分下来要监听的行为如下:
- 获取属性:读取
- 设置属性:写入
- 新增属性:写入
- 删除属性:写入
- 是否存在某个属性:读取
- 遍历属性:读取
# 拦截后对应的处理
不同的行为,拦截下来后要做的事情是不一样的。整体来讲分为两大类:
- 收集器:针对读取的行为,会触发收集器去收集依赖,所谓收集依赖,其实就是建立数据和函数之间的依赖关系
- 触发器:针对写入行为,触发器会工作,触发器所做的事情就是触发数据所关联的所有函数,让这些函数重新执行
下面是不同行为对应的事情:
- 获取属性:收集器
- 设置属性:触发器
- 新增属性:触发器
- 删除属性:触发器
- 是否存在某个属性:收集器
- 遍历属性:收集器
总结起来也很简单,只要涉及到属性的访问,那就是收集器,只要涉及到属性的设置(新增、删除都算设置),那就是触发器。
# 数组中查找对象
因为在进行代理的时候,是进行了递归代理的,也就是说对象里面成员包含对象的话,也会被代理,这就会导致数组中成员有对象的话,是找不到的。原因很简答,比较的是原始对象和代理对象,自然就找不到。
解决方案:先正常找,找不到就在原始对象中重新找一遍
# 数组改动长度
关于数组长度的改变,也会有一些问题,如果是隐式的改变长度,不会触发 length 的拦截。
另外即便是显式的设置 length,这里会涉及到新增和删除,新增情况下的拦截是正常的,但是在删除的情况下,不会触发 DELETE 拦截,因此也需要手动处理。
# 自定义是否要收集依赖
当调用 push、pop、shift 等方法的时候,因为涉及到了 length 属性的变化,会触发依赖收集,这是我们不期望的。
最好的方式,就是由我们来控制是否要依赖收集。
# 图解 EFFECT
effect 方法的作用:就是将 函数 和 数据 关联起来。
回忆 watchEffect
import { ref, watchEffect } from "vue";
const state = ref({ a: 1 });
const k = state.value;
const n = k.a;
// 这里就会整理出 state.value、state.value.a
watchEffect(() => {
console.log("运行");
state;
state.value;
state.value.a;
n;
});
setTimeout(() => {
state.value = { a: 3 }; // 要重新运行,因为是对 value 的写入操作
}, 500);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
effect 函数的设计:
// 原始对象
const data = {
a: 1,
b: 2,
c: 3,
};
// 产生一个代理对象
const state = new Proxy(data, { ... });
effect(() => {
console.log(state.a);
});
2
3
4
5
6
7
8
9
10
11
在上面的代码中,向 effect 方法传入的回调函数中,访问了 state 的 a 成员,然后我们期望 a 这个成员和这个回调函数建立关联。
第一版实现如下:
let activeEffect = null; // 记录当前的函数
const depsMap = new Map(); // 保存依赖关系
function track(target, key) {
// 建立依赖关系
if (activeEffect) {
let deps = depsMap.get(key); // 根据属性值去拿依赖的函数集合
if (!deps) {
deps = new Set(); // 创建一个新的集合
depsMap.set(key, deps); // 将集合存入 depsMap
}
// 将依赖的函数添加到集合里面
deps.add(activeEffect);
}
console.log(depsMap);
}
function trigger(target, key) {
// 这里面就需要运行依赖的函数
const deps = depsMap.get(key);
if (deps) {
deps.forEach((effect) => effect());
}
}
// 原始对象
const data = {
a: 1,
b: 2,
c: 3,
};
// 代理对象
const state = new Proxy(data, {
get(target, key) {
track(target, key); // 进行依赖收集
return target[key];
},
set(target, key, value) {
target[key] = value;
trigger(target, key); // 派发更新
return true;
},
});
/**
*
* @param {*} fn 回调函数
*/
function effect(fn) {
activeEffect = fn;
fn();
activeEffect = null;
}
effect(() => {
// 这里在访问 a 成员时,会触发 get 方法,进行依赖收集
console.log("执行函数");
console.log(state.a);
});
state.a = 10;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
第一版实现,每个属性对应一个 Set 集合,该集合里面是所依赖的函数,所有属性与其对应的依赖函数集合形成一个 map 结构,如下图所示:
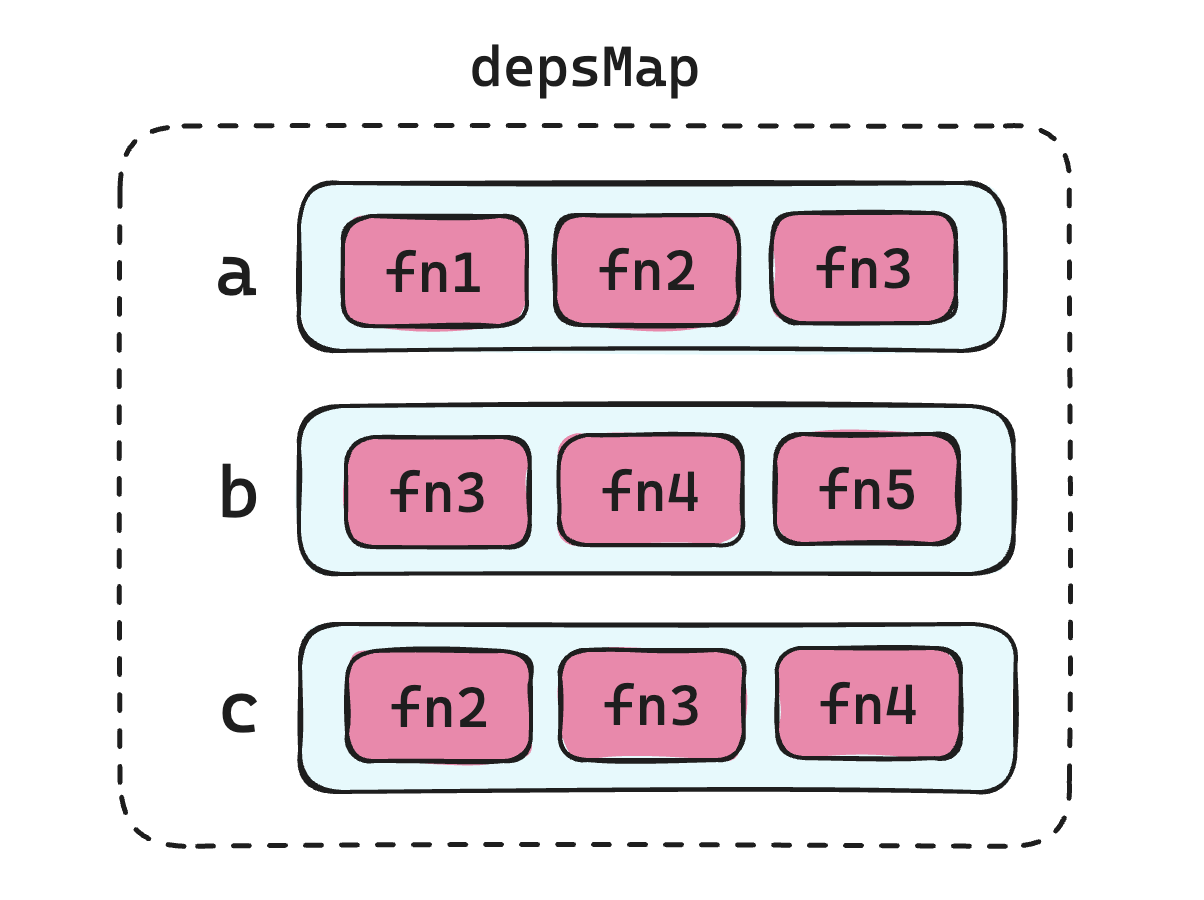
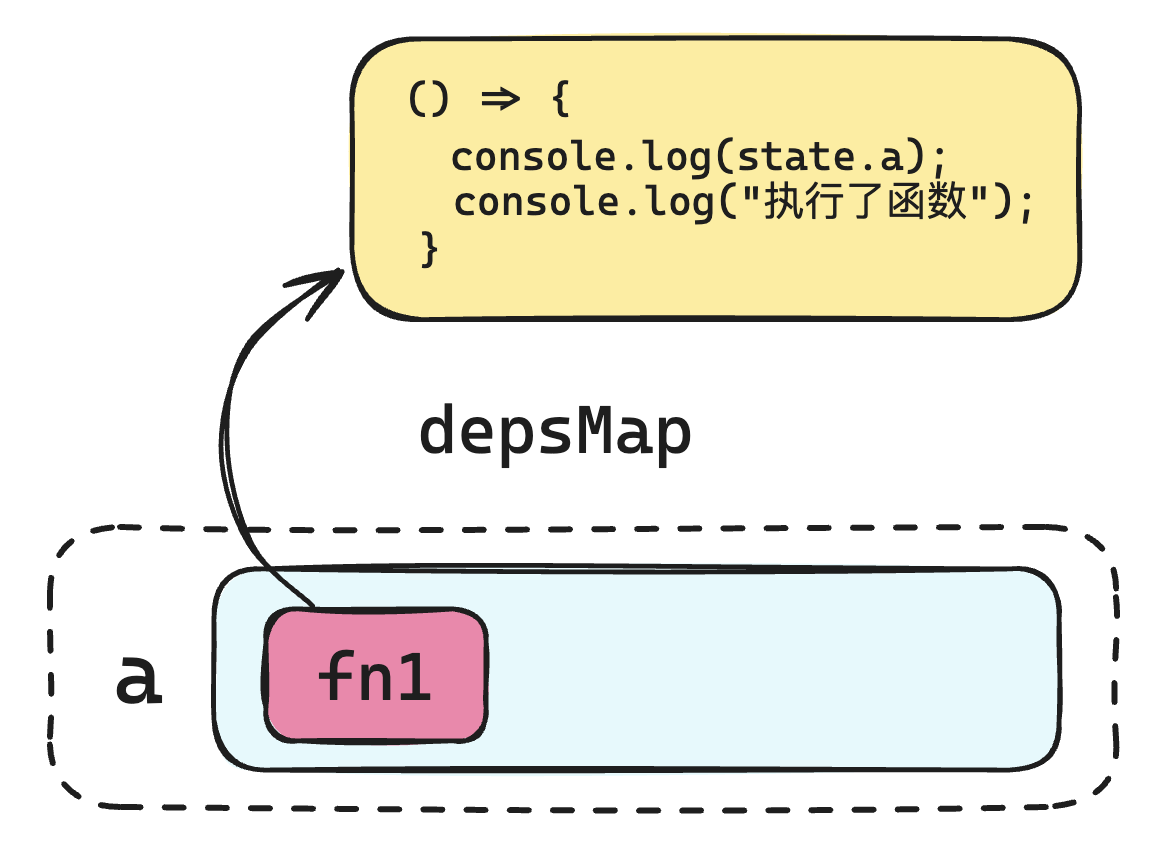
activeEffect 起到一个中间变量的作用,临时存储这个回调函数,等依赖收集完成后,再将这个临时变量设置为空即可。
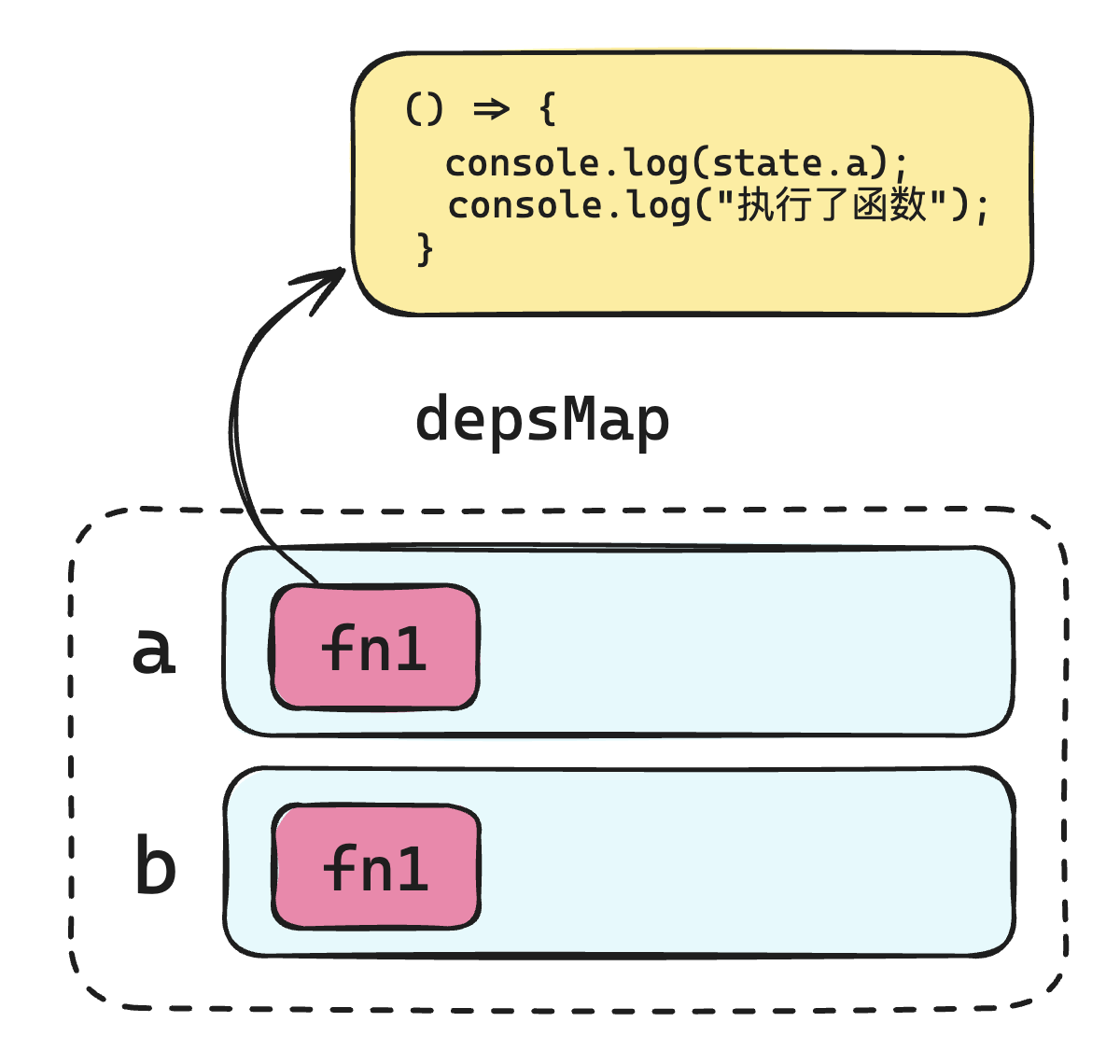
问题一:每一次运行回调函数的时候,都应该确定新的依赖关系。
稍作修改:
effect(() => {
if (state.a === 1) {
state.b;
} else {
state.c;
}
console.log("执行了函数");
});
2
3
4
5
6
7
8
在上面的代码中,两次运行回调函数,所建立的依赖关系应该是不一样的:
- 第一次:a、b
- 第二次:a、c
第一次运行依赖如下:
Map(1) { 'a' => Set(1) { [Function (anonymous)] } }
Map(2) {
'a' => Set(1) { [Function (anonymous)] },
'b' => Set(1) { [Function (anonymous)] }
}
执行了函数
2
3
4
5
6
执行 state.a = 100
依赖关系变为了:
Map(1) { 'a' => Set(1) { [Function (anonymous)] } }
Map(2) {
'a' => Set(1) { [Function (anonymous)] },
'b' => Set(1) { [Function (anonymous)] }
}
执行了函数
Map(2) {
'a' => Set(1) { [Function (anonymous)] },
'b' => Set(1) { [Function (anonymous)] }
}
Map(2) {
'a' => Set(1) { [Function (anonymous)] },
'b' => Set(1) { [Function (anonymous)] }
}
执行了函数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
当 a 的值修改为 100 后,依赖关系应该重新建立,也就是说:
- 第一次运行:建立 a、b 依赖
- 第二次运行:建立 a、c 依赖
那么现在 a 的值明明已经变成 100 了,为什么重新执行回调函数的时候,没有重新建立依赖呢?
原因也很简单,如下图所示:
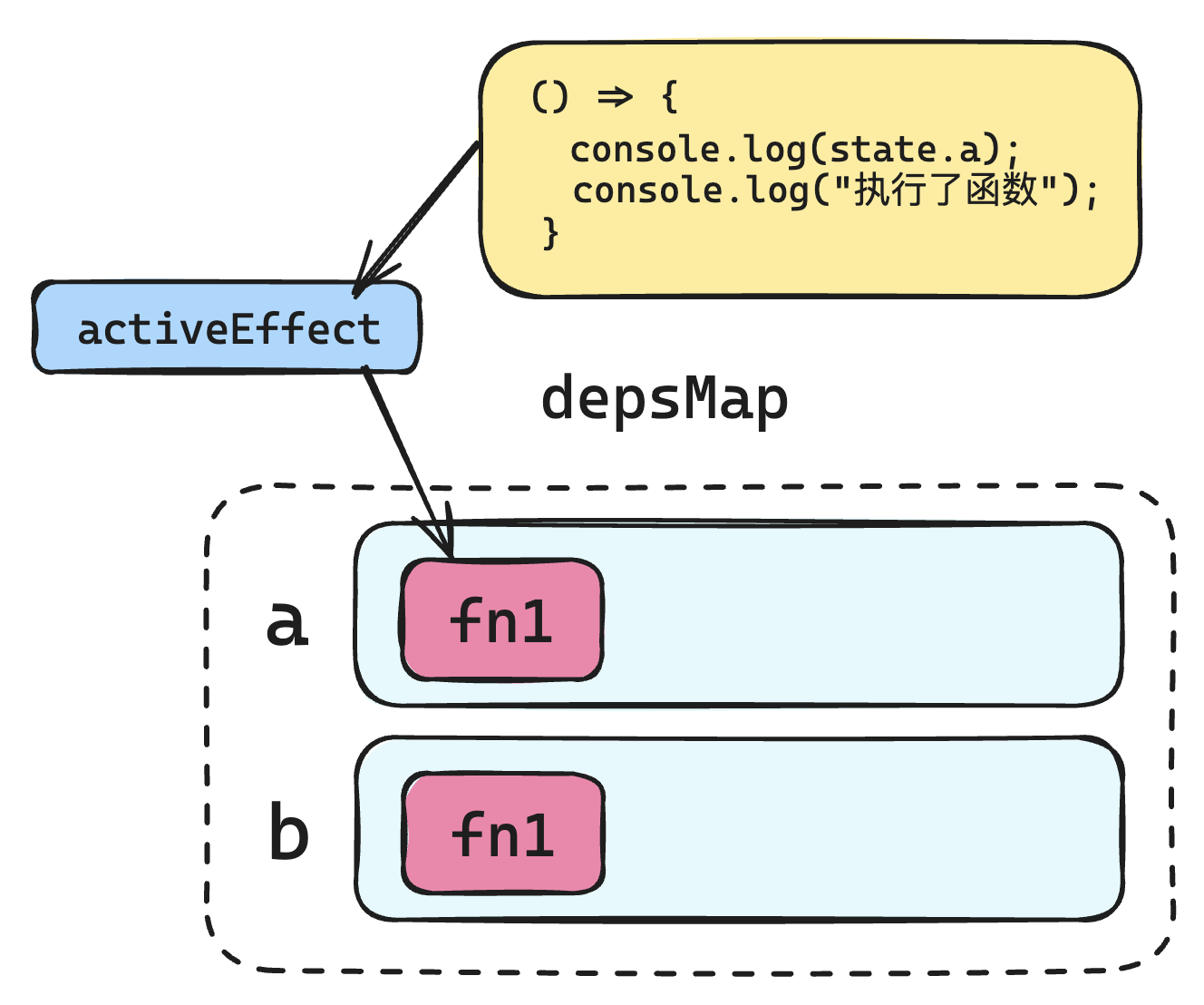
第一次建立依赖关系的时候,是将依赖函数赋值给 activeEffect,最终是通过 activeEffect 这个中间变量将依赖函数添加进依赖列表的。依赖函数执行完毕后,activeEffect 就设置为了 null,之后 a 成员的值发生改变,重新运行的是回调函数,但是 activeEffect 的值依然是 null,这就会导致 track 中依赖收集的代码根本进不去:
function track(target, key) {
if (activeEffect) {
// ...
}
}
2
3
4
5
怎么办呢?也很简单,我们在收集依赖的时候,不再是仅仅收集回调函数,而是收集一个包含 activeEffect 的环境,继续改造 effect:
function effect(fn) {
const environment = () => {
activeEffect = environment;
fn();
activeEffect = null;
};
environment();
}
2
3
4
5
6
7
8
这里 activeEffect 对应的值,不再是像之前那样是回调函数,而是一整个 environment 包含环境信息的函数,这样当重新执行依赖的函数的时候,执行的也就是这个环境函数,而环境函数的第一行就是 activeEffect 赋值,这样就能够正常的进入到依赖收集环节。
如下图所示:
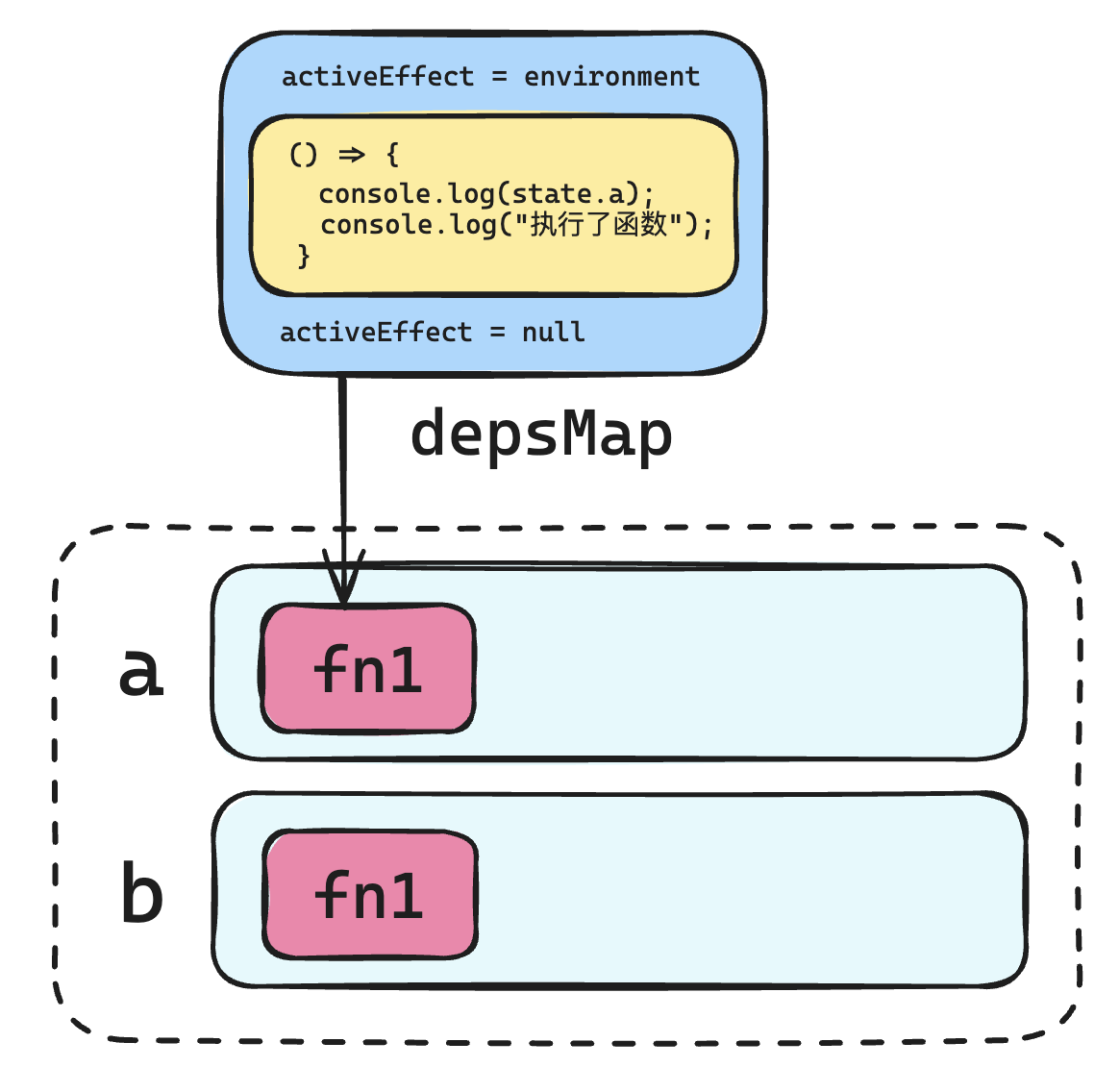
**问题二:**旧的依赖没有删除
解决方案:在执行 fn 方法之前,先调用了一个名为 cleanup 的方法,该方法的作用就是用来清除依赖。
该方法代码如下:
function cleanup(environment) {
let deps = environment.deps; // 拿到当前环境函数的依赖(是个数组)
if (deps.length) {
deps.forEach((dep) => {
dep.delete(environment);
if (dep.size === 0) {
for (let [key, value] of depsMap) {
if (value === dep) {
depsMap.delete(key);
}
}
}
});
deps.length = 0;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
具体结构如下图所示:
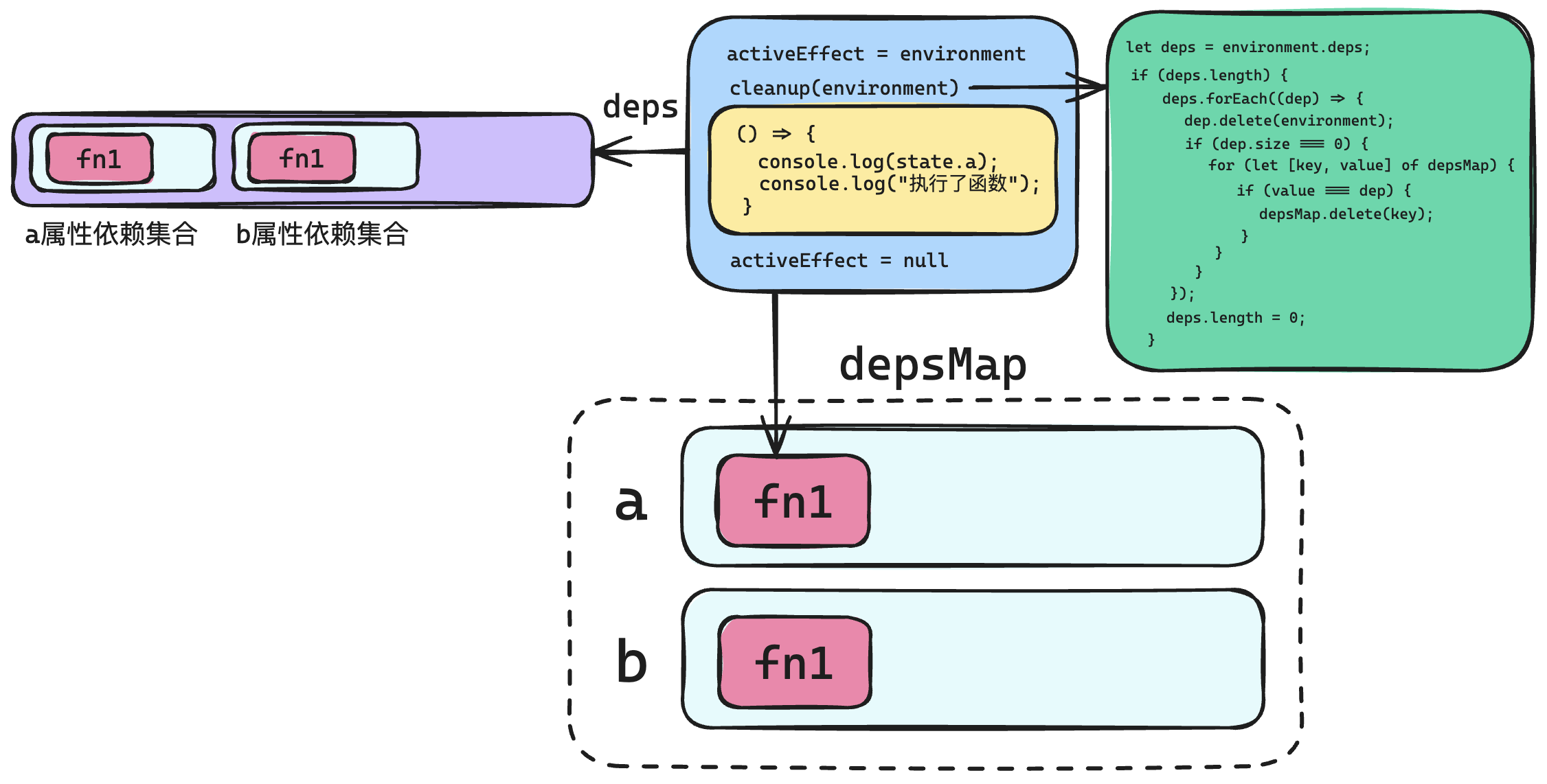
测试多个依赖函数
effect(() => {
if (state.a === 1) {
state.b;
} else {
state.c;
}
console.log("执行了函数1");
});
effect(() => {
console.log(state.c);
console.log("执行了函数2");
});
state.a = 2;
2
3
4
5
6
7
8
9
10
11
12
13
effect(() => {
if (state.a === 1) {
state.b;
} else {
state.c;
}
console.log("执行了函数1");
});
effect(() => {
console.log(state.a);
console.log(state.c);
console.log("执行了函数2");
});
state.a = 2;
2
3
4
5
6
7
8
9
10
11
12
13
14
解决无限循环问题:
在 track 函数中,每次 state.a 被访问时,都会重新添加当前的 activeEffect 到依赖集合中。而在 trigger 函数中,当 state.a 被修改时,会触发所有依赖 state.a 的 effect 函数,这些 effect 函数中又会重新访问 state.a,从而导致了无限循环。具体来讲:
- 初始执行 effect 时,state.a 的值为 1,因此第一个 effect 会访问 state.b,第二个 effect 会访问 state.a 和 state.c。
- state.a 被修改为 2 时,trigger 函数会触发所有依赖 state.a 的 effect 函数。
- 第二个 effect 函数被触发后,会访问 state.a,这时 track 函数又会把当前的 activeEffect 添加到 state.a 的依赖集合中。
- 因为 state.a 的值被修改,会再次触发 trigger,导致第二个 effect 函数再次执行,如此循环往复,导致无限循环。
要解决这个问题,可以在 trigger 函数中添加一些机制来防止重复触发同一个 effect 函数,比如使用一个 Set 来记录已经触发过的 effect 函数:
function trigger(target, key) {
const deps = depsMap.get(key);
if (deps) {
const effectsToRun = new Set(deps); // 复制一份集合,防止在执行过程中修改原集合
effectsToRun.forEach((effect) => effect());
}
}
2
3
4
5
6
7
测试嵌套函数
effect(() => {
effect(() => {
state.a;
console.log("执行了函数2");
});
state.b;
console.log("执行了函数1");
});
2
3
4
5
6
7
8
会发现所建立的依赖又不正常了:
Map(1) { 'a' => Set(1) { [Function: environment] { deps: [Array] } } }
执行了函数2
Map(1) { 'a' => Set(1) { [Function: environment] { deps: [Array] } } }
执行了函数1
2
3
4
究其原因,是目前的函数栈有问题,当执行到内部的 effect 函数时,会将 activeEffect 设置为 null,如下图所示:
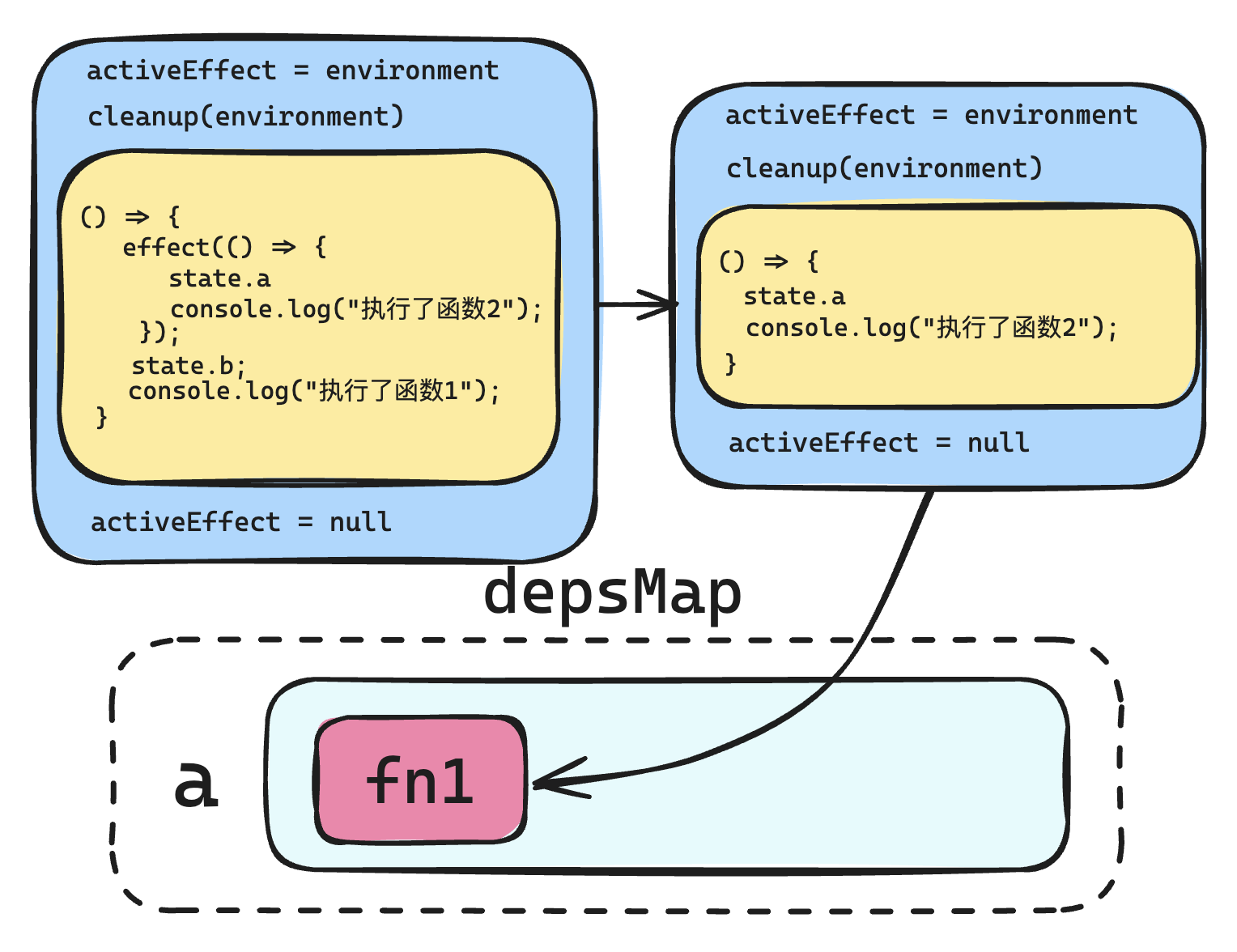
解决方案:模拟函数栈的形式。
# 关联数据和函数
依赖收集
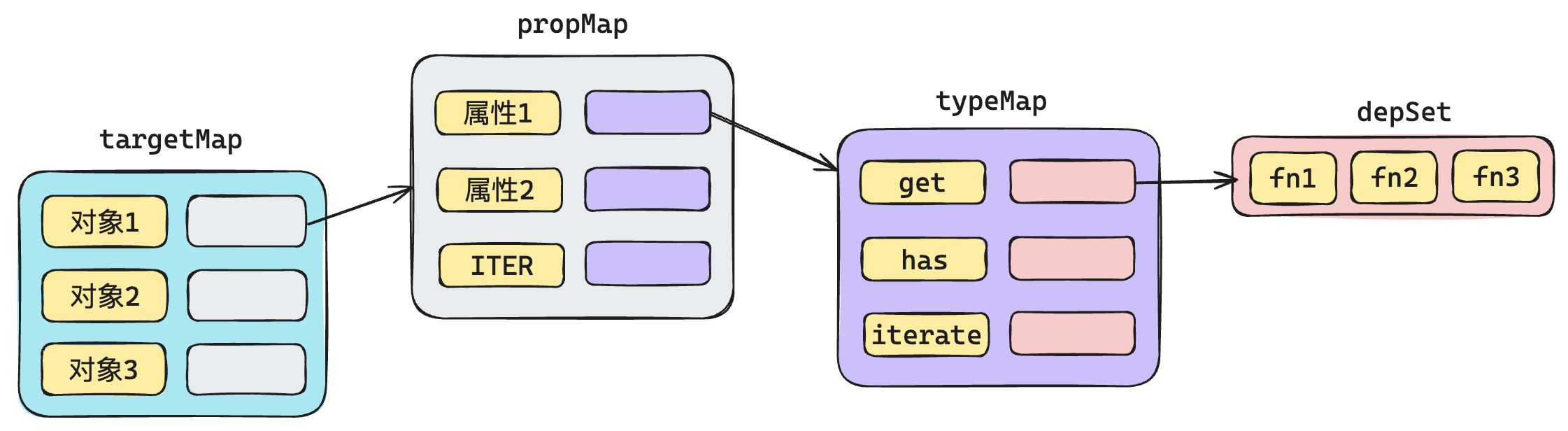
实现 Effect
这里直接给出 Effect 实现:
/**
* 用于记录当前活动的 effect
*/
export let activeEffect = undefined;
export const targetMap = new WeakMap(); // 用来存储对象和其属性的依赖关系
const effectStack = [];
/**
* 该函数的作用,是执行传入的函数,并且在执行的过程中,收集依赖
* @param {*} fn 要执行的函数
*/
export function effect(fn) {
const environment = () => {
try {
activeEffect = environment;
effectStack.push(environment);
cleanup(environment);
return fn();
} finally {
effectStack.pop();
activeEffect = effectStack[effectStack.length - 1];
}
};
environment.deps = [];
environment();
}
export function cleanup(environment) {
let deps = environment.deps; // 拿到当前环境函数的依赖(是个数组)
if (deps.length) {
deps.forEach((dep) => {
dep.delete(environment);
});
deps.length = 0;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
改造 track
之前 track 仅仅只是简单的打印,那么现在就不能是简单打印了,而是进行具体的依赖收集。
注意依赖收集的时候,需要按照上面的设计一层一层进行查找。
改造 trigger
trigger 要做的事情也很简单,就是从我们所设计的数据结构里面,一层一层去找,找到对应的依赖函数集合,然后全部执行一次。
首先我们需要建立一个设置行为和读取行为之间的映射关系:
// 定义修改数据和触发数据的映射关系
const triggerTypeMap = {
[TriggerOpTypes.SET]: [TrackOpTypes.GET],
[TriggerOpTypes.ADD]: [TrackOpTypes.GET, TrackOpTypes.ITERATE, TrackOpTypes.HAS],
[TriggerOpTypes.DELETE]: [TrackOpTypes.GET, TrackOpTypes.ITERATE, TrackOpTypes.HAS],
};
2
3
4
5
6
我们前面在建立映射关系的时候,是根据具体的获取信息的行为来建立的映射关系,那么我们获取信息的行为有:
- GET
- HAS
- ITERATE
这些都是在获取成员信息,而依赖函数就是和这些获取信息的行为进行映射的。
因此在进行设置操作的时候,需要思考一下当前的设置,会涉及到哪些获取成员的行为,然后才能找出该行为所对应的依赖函数。
懒执行
有些时候我们想要实现懒执行,也就是不想要传入 effect 的回调函数自动就执行一次,通过配置项来实现
添加回调
有些时候需要由用户来指定是否派发更新,支持用户传入一个回调函数,然后将要依赖的函数作为参数传递回给用户给的回调函数,由用户来决定如何处理。
# 手写 computed
回顾 computed 的用法
首先回顾一下 computed 的基本用法:
const state = reactive({
a: 1,
b: 2,
});
const sum = computed(() => {
return state.a + state.b;
});
2
3
4
5
6
7
8
const firstName = ref("John");
const lastName = ref("Doe");
const fullName = computed({
get() {
return firstName.value + " " + lastName.value;
},
set(newValue) {
[firstName.value, lastName.value] = newValue.split(" ");
},
});
2
3
4
5
6
7
8
9
10
11
实现 computed 方法
首先第一步,我们需要对参数进行归一化,如下所示:
function normalizeParameter(getterOrOptions) {
let getter, setter;
if (typeof getterOrOptions === "function") {
getter = getterOrOptions;
setter = () => {
console.warn(`Computed property was assigned to but it has no setter.`);
};
} else {
getter = getterOrOptions.get;
setter = getterOrOptions.set;
}
return { getter, setter };
}
2
3
4
5
6
7
8
9
10
11
12
13
上面的方法就是对传入 computed 的参数进行归一化,无论是传递的函数还是对象,统一都转换为对象。
接下啦就是建立依赖关系,如何建立呢?
无外乎就是将传入的 getter 函数运行一遍,getter 函数内部的响应式数据和 getter 产生关联:
// value 用于记录计算属性的值,dirty 用于标识是否需要重新计算
let value,
dirty = true;
// 将 getter 传入 effect,getter 里面的响应式属性就会和 getter 建立依赖关系
const effetcFn = effect(getter, {
lazy: true,
});
2
3
4
5
6
7
这里的 value 用于缓存计算的值,dirty 用于标记数据是否过期,一开始标记为过期方便一开始执行一次计算到最新的值。
lazy 选项标记为 true,因为计算属性只有在访问的之后,才会进行计算。
接下来向外部返回一个对象:
const obj = {
// 外部获取计算属性的值
get value() {
if (dirty) {
// 第一次会进来,先计算一次,然后将至缓存起来
value = effetcFn();
dirty = false;
}
// 返回计算出来的值
return value;
},
set value(newValue) {
setter(newValue);
},
};
return obj;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
该对象有一个 value 访问器属性,当访问 value 值的时候,会根据当前是否为脏值来决定是否重新计算。
目前为止,我们的计算属性工作一切正常,但是这种情况,某一个函数依赖计算属性的值,例如渲染函数。那么此时计算属性值的变化,应该也会让渲染函数重新执行才对。例如:
const state = reactive({
a: 1,
b: 2,
});
const sum = computed(() => {
console.log("computed");
return state.a + state.b;
});
effect(() => {
// 假设这个是渲染函数,依赖了 sum 这个计算属性
console.log("render", sum.value);
});
state.a++;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
执行结果如下:
computed
render 3
computed
2
3
可以看到 computed 倒是重新执行了,但是渲染函数并没有重新执行。
怎么办呢?很简单,内部让渲染函数和计算属性的值建立依赖关系即可。
const obj = {
// 外部获取计算属性的值
get value() {
// 相当于计算属性的 value 值和渲染函数之间建立了联系
track(obj, TrackOpTypes.GET, "value");
// ...
},
// ...
};
return obj;
2
3
4
5
6
7
8
9
10
首先在获取依赖属性的值的时候,我们进行依次依赖收集,这样因为渲染函数里面用到了计算属性,因此计算属性 value 值就会和渲染函数产生依赖关系。
const effetcFn = effect(getter, {
lazy: true,
scheduler() {
dirty = true;
// 派发更新,执行和 value 相关的函数,也就是渲染函数。
trigger(obj, TriggerOpTypes.SET, "value");
},
});
2
3
4
5
6
7
8
接下来添加配置项 scheduler,之后无论是 state.a 的变化,还是 state.b 的变化,都会进入到 scheduler,而在 scheduler 中,重新将 dirty 标记为脏数据,然后派发和 value 相关的更新即可。
完整的代码如下:
import { effect } from "./effect/effect.js";
import track from "./effect/track.js";
import trigger from "./effect/trigger.js";
import { TriggerOpTypes, TrackOpTypes } from "./utils.js";
function normalizeParameter(getterOrOptions) {
let getter, setter;
if (typeof getterOrOptions === "function") {
getter = getterOrOptions;
setter = () => {
console.warn(`Computed property was assigned to but it has no setter.`);
};
} else {
getter = getterOrOptions.get;
setter = getterOrOptions.set;
}
return { getter, setter };
}
/**
*
* @param {*} getterOrOptions 可能是函数,也可能是对象
*/
export function computed(getterOrOptions) {
// 1. 第一步,先做参数归一化
const { getter, setter } = normalizeParameter(getterOrOptions);
// value 用于记录计算属性的值,dirty 用于标识是否需要重新计算
let value,
dirty = true;
// 将 getter 传入 effect,getter 里面的响应式属性就会和 getter 建立依赖关系
const effetcFn = effect(getter, {
lazy: true,
scheduler() {
dirty = true;
trigger(obj, TriggerOpTypes.SET, "value");
console.log("j");
},
});
// 2. 第二步,返回一个新的对象
const obj = {
// 外部获取计算属性的值
get value() {
track(obj, TrackOpTypes.GET, "value");
if (dirty) {
// 第一次会进来,先计算一次,然后将至缓存起来
value = effetcFn();
dirty = false;
}
// 直接计算出来的值
return value;
},
set value(newValue) {
setter(newValue);
},
};
return obj;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# 手写 watch
回顾 watch 的用法
const x = reactive({
a: 1,
b: 2,
});
// 单个 ref
watch(x, (newX) => {
console.log(`x is ${newX}`);
});
// getter 函数
watch(
() => x.a + x.b,
(sum) => {
console.log(`sum is: ${sum}`);
}
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
简单总结起来,就是前面的响应式数据发生变化,重新执行后面的回调函数。回调函数的参数列表中,会传入新的值和旧的值。
另外 watch 还接收第三个参数,是一个选项对象,可以的配置的值有:
- immediate:立即执行一次回调函数
- once:只执行一次
- flush
- post:在侦听器回调中能访问被 Vue 更新之后的所属组件的 DOM
- sync:在 Vue 进行任何更新之前触发
watch 方法会返回一个函数,该函数用于停止侦听
const unwatch = watch(() => {});
// ...当该侦听器不再需要时
unwatch();
2
3
4
实现 watch 方法
首先写一个工具方法 traverse:
function traverse(value, seen = new Set()) {
// 检查 value 是否是对象类型,如果不是对象类型,或者是 null,或者已经访问过,则直接返回 value。
if (typeof value !== "object" || value === null || seen.has(value)) {
return value;
}
// 将当前的 value 添加到 seen 集合中,标记为已经访问过,防止循环引用导致的无限递归。
seen.add(value);
// 使用 for...in 循环遍历对象的所有属性。
for (const key in value) {
// 递归调用 traverse,传入当前属性的值和 seen 集合。
traverse(value[key], seen);
}
// 返回原始值
return value;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
该方法的主要作用是递归遍历一个对象及其所有嵌套的属性,从而触发这些属性的依赖收集。
这个方法在 watch 函数中很重要,因为它确保了所有嵌套属性的依赖关系都能被追踪到,当它们变化时能够触发回调函数。
假设有一个深层嵌套的对象:
const obj = {
a: 1,
b: {
c: 2,
d: {
e: 3,
},
},
};
2
3
4
5
6
7
8
9
那么整个遍历过程如下:
- 由于 obj 是对象,并且没有访问过,会将 obj 添加到 seen 集合里面
- 遍历 obj 的属性:
- 访问 obj.a 是数字,会直接返回,不做进一步的处理
- 访问 obj.b,会进入 traverse(obj.b, seen)
- 由于 obj.b 是对象,并且未被访问过,将 obj.b 添加到 seen 集合中。
- 遍历 obj.b 的属性:
- 访问 obj.b.c 是数字,会直接返回,不做进一步的处理
- 访问 obj.b.d,会进入 traverse(obj.b.d, seen)
- 由于 obj.b.d 是对象,并且未被访问过,将 obj.b.d 添加到 seen 集合中。
- 遍历 obj.b.d 的属性:
- 访问 obj.b.c.e 是数字,会直接返回,不做进一步的处理
在这个过程中,每次访问一个属性(例如 obj.b 或 obj.b.d),都会触发依赖收集。这意味着当前活动的 effect 函数会被记录为这些属性的依赖。
接下来咱们仍然是进行参数归一化:
/**
* @param {*} source
* @param {*} cb 要执行的回调函数
* @param {*} options 选项对象
* @returns
*/
export function watch(source, cb, options = {}) {
let getter;
if (typeof source === "function") {
getter = source;
} else {
getter = () => traverse(source);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在上面的代码中,无论用户的 source 是传递什么类型的值,都转换为函数(这里没有考虑数组的情况)
- source 本来就是函数:直接将 source 赋值给 getter
- source 是一个响应式对象:转换为一个函数,该函数会调用 traverse 方法
接下来定义两个变量,用于存储新旧两个值:
let oldValue, newValue;
好了,接下来轮到 effect 登场了:
const effectFn = effect(() => getter(), {
lazy: true,
scheduler: () => {
newValue = effectFn();
cb(newValue, oldValue);
oldValue = newValue;
},
});
2
3
4
5
6
7
8
这段代码,首先会运行 getter 函数(前面做了参数归一化,已经将 getter 转换为函数了),getter 函数里面的响应式数据就会被依赖收集,当这些响应式数据发生变化的时候,就需要派发更新。
因为这里传递了 scheduler,因此在派发更新的时候,实际上执行的就是 scheduler 对应的函数,实际上也就是这三行代码:
newValue = effectFn();
cb(newValue, oldValue);
oldValue = newValue;
2
3
这三行代码的意思也非常明确:
- newValue = effectFn( ):重新执行一次 getter,获取到新的值,然后把新的值给 newValue
- cb(newValue, oldValue):调用用户传入的换掉函数,将新旧值传递过去
- oldValue = newValue:更新 oldValue
再往后走,代码就非常简单了,在此之前之前,我们先把 scheduler 对应的函数先提取出来:
const job = () => {
newValue = effectFn();
cb(newValue, oldValue);
oldValue = newValue;
};
const effectFn = effect(() => getter(), {
lazy: true,
scheduler: job,
});
2
3
4
5
6
7
8
9
10
然后实现 immediate,如下:
if (options.immediate) {
job();
} else {
oldValue = effectFn();
}
2
3
4
5
immediate 的实现无外乎就是立马派发一次更新。而如果没有配置 immediate,实际上也会执行一次依赖函数,只不过算出来的值算作旧值,而非新值。
接下来执行取消侦听,其实也非常简单:
return () => {
cleanup(effectFn);
};
2
3
就是返回一个函数,函数里面调用 cleanup 将依赖清除掉即可。
你会发现只要前面响应式系统写好了,接下来的这些实现都非常简单。
最后我们再优化一下,添加 flush 配置项的 post 值的支持。flush 的本质就是指定调度函数的执行时机,当 flush 的值为 post 的时候,代表调用函数需要将最终执行的更新函数放到一个微任务队列中,等待 DOM 更新结束后再执行。
代码如下所示:
const effectFn = effect(() => getter(), {
lazy: true,
scheduler: () => {
if (options.flush === "post") {
Promise.resolve().then(job);
} else {
job();
}
},
});
2
3
4
5
6
7
8
9
10
完整代码如下:
import { effect, cleanup } from "./effect/effect.js";
/**
* @param {*} source
* @param {*} cb 要执行的回调函数
* @param {*} options 选项对象
* @returns
*/
export function watch(source, cb, options = {}) {
let getter;
if (typeof source === "function") {
getter = source;
} else {
getter = () => traverse(source);
}
// 用于保存上一次的值和当前新的值
let oldValue, newValue;
// 这里的 job 就是要执行的函数
const job = () => {
newValue = effectFn();
cb(newValue, oldValue);
oldValue = newValue;
};
const effectFn = effect(() => getter(), {
lazy: true,
scheduler: () => {
if (options.flush === "post") {
Promise.resolve().then(job);
} else {
job();
}
},
});
if (options.immediate) {
job();
} else {
oldValue = effectFn();
}
return () => {
cleanup(effectFn);
};
}
function traverse(value, seen = new Set()) {
// 检查 value 是否是对象类型,如果不是对象类型,或者是 null,或者已经访问过,则直接返回 value。
if (typeof value !== "object" || value === null || seen.has(value)) {
return value;
}
// 将当前的 value 添加到 seen 集合中,标记为已经访问过,防止循环引用导致的无限递归。
seen.add(value);
// 使用 for...in 循环遍历对象的所有属性。
for (const key in value) {
// 递归调用 traverse,传入当前属性的值和 seen 集合。
traverse(value[key], seen);
}
// 返回原始值
return value;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
← 响应式和组件渲染本质 指令的本质 →